Data Management Glossary
Metadata Enrichment
What is Metadata Enrichment?
Metadata enrichment is the process of adding contextual, descriptive, or business-relevant information to your existing data to make it more discoverable, understandable, and useful – especially for downstream analytics and AI.
Why Metadata Enrichment Matters for AI
 For AI to work effectively, especially in enterprise environments, it needs relevant, high-quality input data. But unstructured data (like files, images, videos, logs) typically has minimal or inconsistent metadata – just basic system info like file name, owner, and last modified date. (See System Metadata)
For AI to work effectively, especially in enterprise environments, it needs relevant, high-quality input data. But unstructured data (like files, images, videos, logs) typically has minimal or inconsistent metadata – just basic system info like file name, owner, and last modified date. (See System Metadata)
Without metadata enrichment:
- AI tools can’t easily filter or prioritize the right training data
- Sensitive or irrelevant content may be included by mistake
- Data pipelines are bloated, costly, and harder to govern
With metadata enrichment:
- You can tag files with business context (e.g., project name, department, PII status, language, sensitivity)
- AI systems can automatically prioritize, exclude, or fine-tune based on smart metadata
- You’re able to benefit from faster, safer, and more targeted AI data ingestion
How Komprise Enables Metadata Enrichment
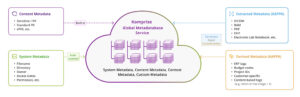
Global Metadatabase
The Komprise Global Metadatabase continuously indexes metadata across all your storage (on-prem and cloud), giving you centralized visibility into billions of unstructured files, without moving the data.
Smart Data Workflows
With Smart Data Workflows, you can:
- Apply tags, labels, or policies based on criteria like file type, usage, owner, location, or content characteristics
- Identify and tag sensitive data (e.g., files with PII or financial info) using custom or external classifiers
- Add custom metadata to drive policy-based automation, such as archiving, moving to AI platforms, or restricting access
Example: Tag and extract .pdf and .tiff files last accessed by R&D in the last 12 months and route them for AI model training, while excluding files with flagged PII. These are use cases Komprise is working customers to develop.
Metadata Enrichment Outcome for Enterprises
By enriching unstructured data with meaningful metadata, Komprise empowers enterprises to:
- Feed AI with curated, relevant, and governed datasets
- Avoid overloading pipelines with noisy or risky data
- Accelerate AI time-to-value while maintaining compliance
Metadata is the new index and Komprise gives enterprises the tools to enrich file and object data at scale, across disprate storage environments and locations.
Why is Komprise Intelligent Management a Better Approach than ETL or iPaaS Tools?
Komprise is better approach to metadata enrichment for unstructured file and object data than traditional ETL or iPaaS tools because it is purpose-built for the scale, complexity, and structure-free nature of unstructured data, while ETL and iPaaS are primarily designed for structured data workflows.
Why Komprise Intelligent Data Management?
 Built for Unstructured Data
Built for Unstructured Data
- ETL/iPaaS tools excel at moving structured data between databases and SaaS apps, but struggle with large-scale file and object storage systems.
- Komprise directly connects to file (NAS) and object (S3, Azure Blob, etc.) storage, indexing billions of files without moving them, and operates at petabyte scale.
Metadata Visibility Without Data Movement
- ETL tools often require data to be moved into a processing environment for metadata to be extracted or transformed. This is slow, expensive, and risky for unstructured data.
- Komprise uses a Global Metadatabase to collect and enrich metadata in place, enabling fast search, tagging, and decision-making without disrupting production systems.
Smart, Policy-Based Enrichment
- ETL/iPaaS workflows require complex manual scripting to enrich data or apply rules, which is brittle and hard to scale.
- Komprise Smart Data Workflows let you automate enrichment based on file attributes, content, access patterns, and third-party classification tools—like tagging files with PII, project names, or compliance labels dynamically. (See Sensitive Data Management.)
No Rehydration or Egress Penalties
- ETL tools may trigger expensive rehydration or data egress costs when accessing archived cloud storage.
- Komprise operates transparently, preserving native file access and avoiding cloud storage “penalties.” (See Transparent Move Technology (TMT))
Enterprise-Ready for AI and Governance
- Komprise is designed for enterprises managing hybrid cloud, multi-vendor storage environments, and prepping data for AI, analytics, governance, and compliance use cases. (See storage agnostic data management.)
- Komprise offers visibility + enrichment + movement + access control—in a single, storage-agnostic platform.

Metadata Enrichment FAQs
What types of custom metadata can be extracted through metadata enrichment for unstructured data?
The value of metadata enrichment depends entirely on how specific and relevant the enriched attributes are to the organization’s use cases. Standard system metadata covering file name, size, owner, and timestamp is available automatically but rarely sufficient for AI data preparation, compliance governance, or content monetization at scale.
Custom metadata extraction through KAPPA data services covers a wide range of domain-specific use cases depending on the industry and file type. In healthcare and life sciences, KAPPA extracts clinical parameters from DICOM headers, sequencing metadata from BAM and FASTQ files, and experiment identifiers from Electronic Lab Notebooks. In media and entertainment, KAPPA extracts embedded image metadata including EXIF, XMP, and IPTC fields, as well as codec, resolution, frame rate, and media order information from video containers. In legal and corporate environments, KAPPA extracts document metadata from PDFs, matter numbers, and sensitivity labels from Microsoft Purview. In research, engineering, and oil and gas, KAPPA extracts project codes, budget identifiers, and ERP or Salesforce record associations from file content. All extracted metadata is stored as custom tags in the Global Metadatabase where it is searchable at the same query speed as standard file attributes across billions of files.
How does metadata enrichment improve AI model accuracy and reduce inferencing costs?
AI models and RAG pipelines perform better when they reason from data that is well-described, precisely curated, and free of noise. Without metadata enrichment, AI systems must evaluate relevance based on file names, directory paths, and basic system attributes that carry little business context. This means models ingest large volumes of data and filter downstream, increasing token usage per inference and reducing the signal-to-noise ratio of every output.
Metadata enrichment addresses this upstream. When files are tagged with project context, sensitivity classification, domain identifiers, and content characteristics before they reach an AI pipeline, AI systems can filter precisely using those tags rather than ingesting broadly and hoping for relevance. Komprise Deep Analytics queries the Global Metadatabase using enriched custom tags as first-class search criteria, performing at the same speed as standard metadata queries across billions of files. This enables AI data curation based on real business context rather than directory structure, reducing the volume of data entering AI pipelines and directly lowering inferencing costs while improving output accuracy. Gartner estimates that up to 60% of enterprise AI projects fail due to inadequate data readiness, and insufficient metadata enrichment is one of the primary causes.
How does metadata enrichment support data governance and compliance for unstructured data?
Governance requirements for unstructured data depend on knowing what files contain, not just where they live. A file classified as containing PII needs different access controls, retention policies, and AI usage restrictions than a file containing public research data. Without metadata enrichment that captures sensitivity classification, content type, and regulatory status as searchable, actionable attributes, governance policies are applied by directory path or file extension rather than by actual content, which produces incomplete and unreliable compliance coverage.
Komprise addresses this by enabling metadata enrichment to serve as the foundation for governance enforcement rather than documentation only. Tags applied through KAPPA data services, Smart Data Workflows sensitive data detection, or manual and API-based tagging are stored in the Global Metadatabase as persistent, searchable attributes that follow the file regardless of which storage tier it occupies. A sensitivity tag applied on-premises stays with the file after tiering to cloud, after migration to a new storage vendor, and after delivery to an AI platform. Komprise Smart Data Workflows use these enriched tags to enforce governance policies automatically, ensuring that files tagged as containing PII are excluded from AI ingestion, files tagged with regulated content are confined to compliant storage locations, and all governance decisions are logged in the Global Metadatabase with full audit trail for regulatory reporting.