Data Management Glossary
Unstructured Data Management
What is Unstructured Data Management?
Unstructured data management is a category of software that has emerged to address the explosive growth of unstructured data in the enterprise and the modern reality of hybrid cloud storage. In the Komprise 2026 State of Unstructured Data Management, 40% of organizations report that they are managing 10PB of data or more. More than half (55%) of organizations are spending more than 30% of their IT budget on data storage.
 Data storage and data backup technology vendors are now recognizing the importance of unstructured data management as data outlives infrastructure and as data mobility is needed to leverage cloud data storage.
Data storage and data backup technology vendors are now recognizing the importance of unstructured data management as data outlives infrastructure and as data mobility is needed to leverage cloud data storage.
Additionally, unstructured data is recognized as the fuel for enterprise AI. Managing it effectively is what makes that fuel usable, trusted, and cost-efficient. See AI-ready data and AI data platform for more details.
What are the requirements for are unstructured data management solutions?
Unstructured data management must be independent and agnostic from data storage, backup, and cloud infrastructure technology platforms. Common requirements include:
- Must go beyond storage efficiency and help create greater data value
- Must be multi-directional
- Must not disrupt users and workflows (learn more about Transparent Move Technology)
- Must create new uses for your data (increasingly powering AI initiatives, for example)
- Must put your data first and avoid vendor lock-In (see native data access)
- Must deliver the right data to AI and analytics services.
An analytics-based unstructured data management solution (see Komprise Intelligent Data Management) brings value by analyzing all data in storage across on-premises, cloud and edge environments to deliver deep insights. This knowledge helps IT managers make establish data lifecycle management policies and better decisions with users in mind, optimize costs and reduce security and regulatory compliance risks. These insights go beyond traditional storage metrics such as latency, IOPS and network throughput. Additionally, the right unstructured data management solution should deliver the right data sets in native format to analytics and AI services.
What are examples of new metrics made possible with unstructured data management software?
- Top data owners / users: See trends in usage and and possible compliance issues, such as individual users storing excessive video files or PII files being stored in an insecure location.
- Common file types: The ability to see data by file extension eases the process of finding all files related to a project and can inform future research initiatives. This could be as simple as finding all the log files, trace files or extracts from a given application or instrument and moving them to a data lake for analysis.
- Storage costs for chargeback or showback: Whether for chargeback requirements or not, stakeholders should understand costs in their department and be able to view metrics. This will help identify areas where low-cost storage or data tiering to archival storage is a viable cost-reduction opportunity.
- Data growth rates: High level metrics on data growth keeps IT and business heads on the same page so they can collaborate on data management decisions. Understand which groups and projects are growing data the fastest and ensure that data creation/storage is appropriate according to its overall business priority.
- Age of data and access patterns. In most enterprises, 60-80% of data is “cold” and hasn’t been accessed in a year or more. Metrics showing percentage of cold versus warm versus hot data are critical to ensure that data is living in the right place at the right time according to its business value and to optimize costs.
Read: File Data Metrics to Live By
Beyond cost optimization, can unstructured data management tools and practices help deliver new value from data?
Yes. Unstructured data is the fuel needed for AI, yet its difficult to leverage because unstructured data is hard to find, search across, and move due to its size and distribution across hybrid cloud environments. Tagging and automation can help prepare unstructured data for AI and big data analytics programs. Tactics include:
- Preprocess data at the edge so it can be analyzed and tagged with new metadata before moving it into a cloud data lake. This can drastically reduce the wasted cost and effort of moving and storing useless data and can minimize the occurrence of data swamps.
- Applying automation to facilitate data segmentation, cleansing, search and enrichment. You can do this with data tagging, deletion or tiering of cold data by policy and moving data into the optimal storage where it can be ingested by big data and ML tools. A leading new approach to is the ability to initiate and execute data workflows.
- Use a solution that persists metadata tags as data moves from one location to another. For instance, files tagged as containing key project keywords by a third-party AI service should retain those tags indefinitely so that a new research team doesn’t have to run the same analysis over again — at high cost. Komprise Intelligent Data Management has these capabilities.
- Plan appropriately for large-scale data migration efforts with thorough diligence and testing. This can prevent common networking and security issues that delay data migrations and introduce errors or data loss.
Read the interview with Komprise cofounder and COO: AI Data Pipelines Could Use a Hand from our Features, says Komprise.

What Tools Bring Unstructured Data to AI?
Three categories of tools typically sit in an AI data pipeline: data preparation and ETL tools, vector databases and embedding tools, and RAG pipeline frameworks. Each has a gap when it comes to unstructured data. Gartner notes that traditional data preparation and ETL tools were built to ingest and transform structured data, with limited support for PDFs, HTML, text, audio, and video files, the formats that make up most enterprise unstructured data. See ETL for how this gap plays out in practice.
Vector databases, embedding tools, and solve a different problem. They store and retrieve data after it has already been chunked, vectorized, and turned into vector embeddings. None of these tools discover, classify, or govern the raw file and object data sitting across NAS and cloud storage before it reaches that stage. That earlier step, called AI data ingestion, is what determines whether the data these tools receive is relevant, current, and safe to use.
Komprise brings unstructured data to AI at that ingestion point. The Global Metadatabase indexes file and object data across every NAS and cloud environment, giving Deep Analytics a continuously updated view to search and classify against. Smart Data Workflows then curate, tag, and deliver the right data sets, with KAPPA data services extracting domain-specific metadata from file content automatically. Komprise Intelligent AI Ingest delivers data 2X faster into these downstream AI pipelines, and Transparent File Tables exposes file and object data as Apache Iceberg tables directly in Snowflake, Databricks or other open data lakehouse platforms, without copying raw files first. See AI Data Pipelines and Zero-Copy Data Architecture for how this fits together, and AI Data Platform for where this ingestion layer sits relative to metadata, classification, enrichment, and delivery.
Source: Gartner, “Four Key Pillars of a Data-Centric Approach to AI“
ETL, vector database, and RAG tools each handle one stage of the AI pipeline, but none of them discover, classify, or govern unstructured data before it gets there. Here is how that gap compares to the Komprise approach:
| Evaluation Criteria | Without Komprise (ETL, Vector DB, and RAG Tools Alone) | With Komprise |
|---|---|---|
| Storage and format coverage | Built for structured, relational data. Limited or manual support for PDFs, images, audio, video, and other file formats across NAS and object storage. | Indexes file and object data natively across any combination of on-premises NAS and cloud storage, regardless of format. |
| Discovery before delivery | Assumes a data set has already been selected and handed off. No mechanism to find or classify unstructured data still sitting in storage silos. | The Global Metadatabase and Deep Analytics discover and classify data across the full estate before anything moves. |
| Freshness | Point-in-time exports. Data pipelines only reflect whatever was captured at ingestion time. | Continuously updated index and workflows keep AI pipelines fed with current data, not a one-time snapshot. |
| Metadata and classification | Chunking, embedding, and vectorization operate on content only. Little to no file-level or domain-specific metadata carried forward. | KAPPA data services extract domain-specific metadata from file content automatically, stored alongside system metadata in the Global Metadatabase. |
| Governance and sensitive data | Typically runs after data has already left storage, with no built-in scan for PII or sensitive content before delivery. | Smart Data Workflows scan file content for PII and sensitive data using 68 built-in scanners plus keyword and regex matching, before delivery. |
| Path to AI and lakehouse delivery | Requires a separate copy or ETL step to land data in a lakehouse or vector database. | Transparent File Tables exposes file and object data as Apache Iceberg tables directly in Snowflake and Databricks, with no raw file copy required. Komprise Intelligent AI Ingest delivers data 2X faster into AI pipelines. |
| Scale | Designed for project-level or departmental data sets, not hundreds of petabytes across a global file and object estate. | Proven at 100 petabytes and above across heterogeneous storage. |
What is the State of Unstructured Data Management?
Download the latest report here.
Unstructured data management has evolved since this first report was published in in 2021 — from data storage cost savings through storage optimization and efficiency to sensitive data detection to AI data preparation and intelligent AI ingestion.
In August 2021, Komprise published the first State of Unstructured Data Management Report.

Highlights of the 2021 Unstructured Data Management Report
Unstructured Data is Growing, as are its Costs

- 65.5% of organizations spend more than 30% of their IT budgets on data storage and data management.
- Most (62.5%) will spend more on storage in 2021 versus 2020.
Getting More Unstructured Data to the Cloud is a Key Priority

- 50% of enterprises have data stored in a mix of on-premises and cloud-based storage.
- Top priorities for cloud data management include: migrating data to the cloud (56%) cutting storage and data costs (46%) and governance and security of data in the cloud (41%).
IT Leaders Want Visibility First Before Investing in More Data Storage
- Investing in analytics tools was the highest priority (45%) over buying more cloud or on-premises storage or modernizing backups.
- One-third of enterprises acknowledge that over 50% of data is cold while 20% don’t know, suggesting a need to right-place data through its lifecycle.
Unstructured Data Management Goals & Challenges: Visibility, Cost Management and Data Lakes
- 44.9% wish to avoid rising costs.
- 44.5% want better visibility for planning.
- 42% are interested in tagging data for future use and enabling data lakes.

2022 State Unstructured Data Management Report
In August 2022, the 2nd annual State of Unstructured Data Management Report Finds 65% of Enterprise IT Leaders are Investing in Unstructured Data Analytics. The Top 5 trends from the report are summarized here. They are:
- User Self-Service: In data management, self-service typically refers to the ability for authorized users outside of storage disciplines to search, tag and enrich and act on data through automation—such as a research scientist wanting to continuously export project files to a cloud analytics service.
- Moving Data to Analytics Platforms: A majority (65%) of organizations plan to or are already delivering unstructured data to their big data analytics platforms.
- Cloud File Storage Gains Favor: Cloud NAS topped the list for storage investments in the next year (47%).
- User Expectations Beg Attention: Organizations want to move data without disrupting users and applications (42%).
- IT and Storage Directors want Flexibility: A top goal for unstructured data management (42%) is to adopt new storage and cloud technologies without incurring extra licensing penalties and costs, such as cloud egress fees.

State of Unstructured Data Management 2023: GenAI Arrives
In September 2023, Komprise published the 3rd annual State of Unstructured Data Management report:
The coverage focused on the fact that 66% of respondents said preparing data storage and data management for AI and GenerativeAI in general is a top priority and challenge.
- Data governance is top enterprise priority when introducing AI
- AI: Intelligent data needs intelligent solutions
- Nearly a third of enterprises are already prepping for AI
- Getting Data Governance Right Top AI Priority in 2023

State of Unstructured Data Management 2024: IT Infrastructure on a Budget
Highlights of the Survey:
- Nearly 50% of enterprises are storing more than 5PB of unstructured data and nearly 30% have more than 10PB.
- The top priorities for data storage in the next year include cost optimization (54%), preparing for AI (51%) and investing in data management and data mobility (41%).
- As in 2023, moving data without disruption to users/apps is the top technical unstructured data management challenge (54%), followed by using AI to classify and segment data (48%).
- Prepping for AI is the top business challenge for unstructured data management (57%).
- Only 13% restrict what corporate data can be used in AI, while 31% have no restrictions for users, apps or data in AI.
- Nearly half (44%) are creating AI-ready infrastructure and 32% are building their own learning models.
- Only 30% are increasing the IT budget to support AI projects.
- The leading challenge in prepping data for AI is managing governance/security concerns (45%), followed by data classification and tagging (41%).
- The leading tactic to address AI data concerns is to upgrade data storage/data management technologies (53%).
- AI data governance/security is the top future capability (47%) for unstructured data management, up from 28% in 2023.
- Nearly 60% need more staff with skills related to security, compliance and sensitive data.

State of Unstructured Data Management 2026: AI Governance and Security
In the 5th annual Komprise survey, 40% of IT and storage leaders said they’re storing at least 10 petabytes of unstructured data, the equivalent of two trillion songs or 10 trillion books. Strategies for 2026 include:
- The majority (40%) will increase their IT budget to pay for AI, compared with 30% in 2024.
- To meet security and AI requirements, IT leaders will invest in upgrading data storage and data management platforms (64%), versus 53% in 2024.
- Two-thirds (58%) are creating an internal task force of IT, security, legal and others to develop an AI strategy.
- Nearly half will be adding staff, with a focus on hiring IT infrastructure leaders focused on developing the AI foundation (53%), along with hiring engineers and developers with AI expertise (49%).
Why do you need to manage your unstructured data?
Unstructured data is growing every day at a truly astonishing rate. Today, 85% of the world’s data is unstructured data.
And it’s more than doubling, every two years.
You need to manage unstructured data because it makes up most enterprise data and drives most storage cost, risk, and AI complexity.
Without active management, cold and duplicate files accumulate on expensive primary storage, increasing infrastructure spend, backup costs, and ransomware exposure. At the same time, sensitive data remains hidden, and AI initiatives struggle with siloed, poorly classified content.
Effective unstructured data management reduces data storage costs, improves security and compliance, and makes data accessible and usable for analytics and GenAI.
If you do manage unstructured data effectively, you unlock:
- Lower storage and backup costs
- Reduced security exposure
- Faster AI and analytics initiatives
- Better governance and compliance
- Sustainable data growth
The importance of an unstructured data strategy for enterprise
In a an interview, Komprise co-founder and COO Krishna Subramanian defined unstructured data this way:
Unstructured data is any data that doesn’t fit neatly into a database, and isn’t really structured in rows and columns. So every photo on your phone, every X-ray, every MRI scan, every genome sequence, all the data generated by self-driving cars – all of that is unstructured data. And perhaps more relevant to more businesses, artificial intelligence (AI) and machine learning (ML) – they depend on, and usually output, unstructured data too.
In part two of the interview, she noted:
Unstructured data doesn’t have a common structure. But it does have something called metadata. So every time you take a picture on your phone, there’s certain information that the phone captures, like the time of day, the location where the picture was taken, and if you tag it as a favorite, it’ll have that metadata tag on it too. It might know who’s in the photo, there are certain metadata that are kept.
All filing systems store some metadata about the data. A product like Komprise Intelligent Data Management has a distributed way to search across all the different environments where you’ve stored data, and create a index of all that metadata around the data. (See Global Metadatabase) And that in itself is a difficult problem, because again, unstructured data is so huge. A petabyte of data might be a few billion files, and a lot of these customers are dealing with tens to hundreds of petabytes.
So you need a system that can create an efficient index of hundreds of billions of files that could be distributed in different places. You can’t use a database, you have to have a distributed index, and that’s the technology we use under the hood, but we optimize it for this use case. So you create a global index.
Learn more about unstructured data tagging.
The Future of Unstructured Data Management
In an end of the year blog post, Komprise executives review unstructured data management and data storage predictions for 2023 and the implications of adopting data services, processing data at the edge, multi-cloud challenges, the importance of getting smart data migration strategies, and more.
Here are the predictions for unstructured data management in 2024. Clearly AI has emerged as a top requirement, as summarized in this industry analyst interview: AI infrastructure and independent data management are on trend.
Here are 2025 predictions, which again focus on AI and AI Data Governance.

What are the best unstructured data management tools?
The best unstructured data management tool depends on your environment, business goals, and how you plan to use your data. Some organizations prioritize lowering storage costs, others need faster migrations, stronger governance, better ransomware readiness, or preparing data for AI and analytics.
Because unstructured data often spans NAS, object storage, cloud, and SaaS platforms, many enterprises benefit most from a storage-agnostic solution that works across vendors and environments rather than a tool tied to a single storage platform.
Below are five common categories of unstructured data management tools and where they fit.
1. Storage-Agnostic Unstructured Data Management Platforms
Best for enterprises with multi-vendor environments that need visibility, mobility, cost optimization, governance, and AI data readiness across file and object storage. This is where Komprise leads. See the 2025 Coldago map:
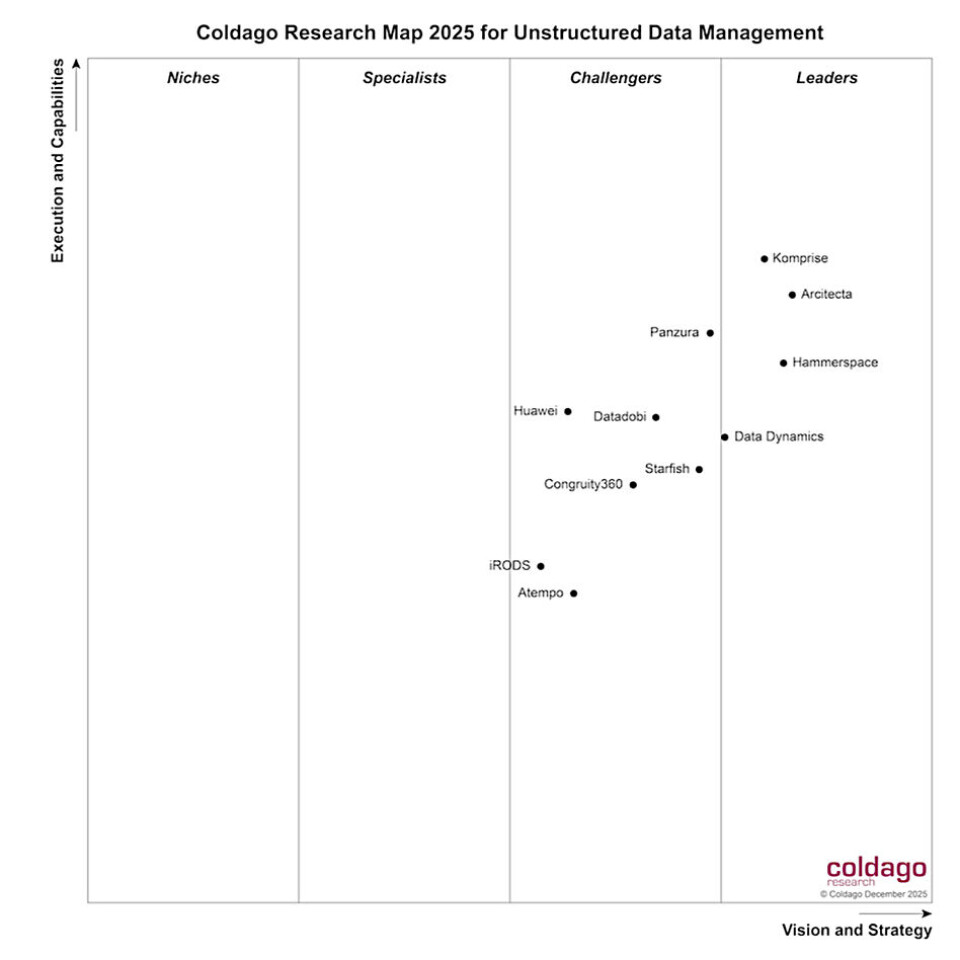
Why this category matters:
These platforms avoid vendor lock-in and can help organizations manage data consistently across on-premises and cloud storage.
Why Komprise stands out:
Komprise combines analytics-driven tiering, transparent data movement, sensitive data workflows, and a Global Metadatabase to help reduce costs while making data easier to use for AI and analytics.
2. Storage-Centric Unstructured Data Management Tools
Best for organizations standardized on one storage vendor that want native tools tightly integrated with their infrastructure.
Examples:
- NetApp ONTAP tools
- Dell Technologies PowerScale / ECS tools
- Hewlett Packard Enterprise Alletra / Ezmeral tools
Considerations:
These tools can work well inside one ecosystem but may be less flexible in mixed environments or during future migrations.
3. Public Cloud Storage Management Tools
Best for cloud-native organizations managing unstructured data in hyperscaler environments.
Examples:
- Amazon Web Services S3 lifecycle policies, Macie, Storage Lens
- Microsoft Azure Blob lifecycle management, Purview
- Google Cloud Cloud Storage lifecycle tools
Considerations:
Strong for cloud-native operations, but costs and complexity can increase in hybrid or multi-cloud environments.
4. Backup, Archive, and Governance Platforms
Best for long-term retention, compliance, and recovery use cases.
Examples:
- Veritas
- Commvault
- Rubrik
Considerations:
Excellent for protection and retention, but not always optimized for active data management or AI data preparation.
5. Data Catalog and Analytics Platforms
Best for discovering, classifying, and analyzing large data estates. Historically vendors in this category have focused on structured and semi-structured data.
Examples:
- Snowflake
- Databricks
- Collibra
Considerations:
Strong for structured and semi-structured analytics workflows, but often require another layer to manage file data at scale.
How to Choose the Right Unstructured Data Management Tool?
Ask these questions:
- Do you have multiple storage vendors or clouds?
- Is storage cost reduction a top priority?
- Do you need file migrations or refresh planning?
- Are you preparing unstructured data for AI?
- Do you need governance or sensitive data detection?
- Do you want to avoid vendor lock-in?
Why Storage-Agnostic Unstructured Data Management Matters
Most enterprises do not operate in a single storage environment. They manage data across:
- NAS platforms
- Object storage
- Public cloud
- SaaS repositories
- Remote offices and edge sites
A storage-agnostic platform like Komprise Intelligent Data Management gives organizations flexibility to optimize costs, move data freely, and prepare valuable unstructured data for AI, without being tied to one vendor ecosystem.
What are the best ways to manage unstructured data in the enterprise?
Effective enterprise unstructured data management requires five connected capabilities working together rather than point solutions addressing individual problems in isolation. Here are 5 ways to manage unstructured data in the enterprise:
- Visibility. The foundation of any unstructured data management strategy is knowing what data exists, where it lives, who owns it, how old it is, and how it is being used. Without a unified view across all NAS and cloud storage environments, every other management decision is based on estimates rather than facts. Komprise scans across multi-vendor NAS and cloud environments to build a continuously updated inventory in the Global Metadatabase, giving IT teams a single view of the entire unstructured data estate.
- Classification. Once data is visible, it needs to be classified by type, sensitivity, business context, and value. Classification answers the questions that drive every downstream decision: which data is cold and can be tiered, which is sensitive and requires governance, which is ROT data that should be deleted, and which is valuable enough to prepare for AI pipelines. Komprise Deep Analytics searches the Global Metadatabase using metadata and custom tags to classify data precisely at petabyte scale. For domain-specific classification, KAPPA data services extract custom metadata from file content automatically.
- Lifecycle management. Unstructured data that is not actively governed accumulates indefinitely. Most enterprises find that 60-70% of their NAS data has not been accessed in over 90 days. Effective lifecycle management means applying automated, policy-based rules that continuously move cold data to lower-cost storage, identify and address ROT data, enforce retention schedules, and right-place data based on its actual value and access patterns. Komprise Intelligent Data Management applies lifecycle policies automatically based on data attributes such as last accessed time, file type, size, and owner, with no manual intervention required.
- Governance and compliance. Unstructured data often contains sensitive content including PII, regulated healthcare records, confidential IP, and financial data. Managing this data means knowing where sensitive content lives, ensuring it does not reach unauthorized AI systems or applications, and maintaining an auditable record of all data management actions for regulatory compliance. Komprise Smart Data Workflows can be created to detect and classify sensitive data across file and object storage, and the Global Metadatabase maintains a complete audit trail of all data movement and classification decisions.
- AI data preparation. Increasingly, the goal of unstructured data management is not just cost control and compliance but making data usable for AI. This means curating relevant, well-classified datasets, enriching them with metadata, delivering them to AI platforms in native format, and ensuring that governed workflows run continuously so AI pipelines always receive current data rather than a one-time snapshot. Komprise Smart Data Workflows automate this end to end, from discovery through delivery.
How do enterprises manage unstructured data at petabyte scale?
Managing unstructured data at petabyte scale requires a fundamentally different approach than managing it at terabyte scale. Manual processes, scheduled audits, and point tools that work acceptably in smaller environments break down entirely when the data estate spans billions of files across dozens of NAS volumes and multiple cloud environments. Three principles define successful petabyte-scale unstructured data management.
First, automation over manual processes. No team can manually classify, tier, or govern billions of files. Every data management decision at petabyte scale must be driven by policy-based automation that runs continuously without human intervention. Tiering policies based on last accessed time automatically move cold data off primary storage as it ages. Classification policies apply tags and governance labels as new data arrives. AI data workflow policies continuously curate and deliver datasets to AI platforms on a defined schedule. Komprise Intelligent Data Management delivers this automation across the full unstructured data lifecycle, proven at 100 petabytes and above.
Second, a unified metadata layer across all storage environments. At petabyte scale, unstructured data is never in one place. It spans multiple NAS vendors, multiple cloud providers, and often multiple geographic locations. Managing it requires a single metadata index that spans all of these environments simultaneously, so that policies, search queries, and governance actions can be applied consistently regardless of where data lives. The Komprise Global Metadatabase provides this unified layer, indexing all file and object data across any combination of on-premises NAS and cloud storage and making it searchable by any metadata or custom tag criteria.
Third, analytics-first decision making. Buying more storage, migrating everything, or applying broad deletion policies without first understanding what data exists and how it is being used leads to wasted spend, operational disruption, and data loss risk. At petabyte scale, every data management action should be preceded by analytics that quantify the opportunity, model the impact, and identify exactly which data qualifies for each action. Komprise provides this analytics foundation, scanning the full data estate and modeling the cost and capacity impact of different management strategies before any data is moved. For migration specifically, the Komprise ACE tool assesses the customer environment before any data is scanned or moved, identifying network topology, potential bottlenecks, and performance constraints that could affect a petabyte-scale migration.
Enterprises that apply these three principles consistently find that petabyte-scale unstructured data management becomes a continuous operational practice rather than a series of expensive, disruptive one-time projects.
What is the best unstructured data management tool?
It depends on your goals. Enterprises with mixed storage environments often benefit most from a storage-agnostic platform. The right tool should provide unified visibility across all NAS and cloud environments, automate data lifecycle policies, and connect directly to AI data workflows without requiring separate tools for each storage vendor.
Why is storage-agnostic important for managing unstructured data?
It avoids lock-in and enables consistent management across vendors and clouds. With most enterprises running multiple NAS vendors alongside AWS, Azure, and Google Cloud simultaneously, a platform tied to one vendor’s ecosystem cannot provide the unified visibility or consistent policy enforcement that petabyte-scale unstructured data management requires.
Read: 5 Ways to Boost Unstructured Data Value: The Komprise Data Experience
Can cloud-native tools replace unstructured data management platforms?
They can help in single-cloud environments, but many organizations still need cross-platform visibility and control. Cloud-native tools from AWS, Azure, and Google Cloud manage data well within their own environments but have no visibility into on-premises NAS, competing cloud providers, or the file-level metadata context needed to drive intelligent tiering, AI data curation, and compliance governance across a hybrid estate.
Can unstructured data management tools help with AI?
Yes. They can identify, organize, and deliver valuable file data for AI and analytics workflows. With up to 60% of enterprise AI projects failing due to poor data readiness according to Gartner, the ability to classify, curate, govern, and deliver the right unstructured datasets to AI platforms is one of the most important capabilities an enterprise data management platform can provide today.
How is Komprise different?
Komprise Intelligent Data Management combines cost optimization, transparent mobility, governance workflows, and AI-ready metadata across heterogeneous storage. It is the only platform that connects a continuously updated Global Metadatabase spanning all NAS and cloud environments to automated data mobility policies and governed AI data workflows, proven at 100 petabytes and above.
No stubs. No disruption to users or applications. No lock-in. Open standards.
Why is unstructured data management important?
Unstructured data management is important because it directly impacts cost, compliance, and business value — especially in the AI era.
Key reasons:
- It’s the majority of enterprise data: Roughly 80–90% of enterprise data is unstructured (files, emails, images, video, sensor data). Without management, it grows unchecked, driving up storage costs.
- Cost control & storage optimization: Keeping all data on expensive, high-performance storage is wasteful. Classifying and moving cold or unused data to cheaper tiers can save millions annually.
- Data governance & compliance: Regulations (GDPR, HIPAA, CCPA) require knowing what data you have, where it lives, and who can access it. Poor oversight risks fines and reputational damage.
- AI readiness: Feeding AI all your unstructured data is inefficient and risky — irrelevant or poor-quality data can lead to inaccurate results. Management ensures only the right, trusted datasets are used.
- Faster data access & productivity: Well-managed data is easier to find, share, and analyze, accelerating business workflows and innovation.
Unstructured data management shifts data from being a hidden liability to a strategic asset — enabling organizations to reduce cost, mitigate risk, and unlock value for analytics and AI.
What is the role of unstructured data management in what Gartner calls DSMS?
In Gartner’s view of Data Storage Management Services (DSMS), unstructured data management plays a central, enabling role because most of the storage management challenge today comes from the explosive growth of file and object data.
Here’s how it fits:
1. Unstructured Data Is the Majority of What DSMS Manages
Gartner notes that 70–90% of enterprise data is unstructured—spanning files, images, videos, logs, scientific data, and more. DSMS strategies that focus only on block storage or structured datasets won’t solve the dominant cost, performance, and compliance challenges. Unstructured Data Management (UDM) extends DSMS beyond capacity and performance to data awareness—knowing what you have, where it is, and how it’s being used.
2. UDM Enables Intelligent Tiering and Cost Optimization
In Gartner’s DSMS framework, a key service is storage optimization.
UDM solutions like Komprise Intelligent Data Management bring file-level analytics and policy-based movement across storage tiers (on-prem, NAS, object, cloud) to cut costs without disrupting access. Without this insight, DSMS risks overprovisioning expensive storage for cold or inactive data.
3. UDM Adds Context for Governance, Compliance, and Security
DSMS includes data protection and governance as core functions. UDM enriches metadata—beyond file size and location—to include sensitivity, owner, access history, and content classification. This allows DSMS to enforce retention, privacy (e.g., GDPR/CCPA), and security policies more accurately.
4. UDM Powers DSMS for the AI Era
Gartner now emphasizes that DSMS is not just about storage cost control—it’s also about delivering the right data to AI, analytics, and digital transformation projects. UDM enables DSMS to curate, classify, and prepare unstructured datasets so AI models aren’t trained on irrelevant or risky data. This bridges storage management with data engineering—something Gartner sees as essential for AI success.
5. Business Outcomes of Integrating UDM into DSMS
- Lower TCO – Reduce cloud and on-prem storage spend by moving inactive data to lower-cost tiers.
- Reduced Risk – Identify and govern sensitive or orphaned data.
- Faster AI/Analytics Projects – Deliver clean, relevant datasets directly from storage infrastructure.
- Improved SLA Compliance – Ensure the right data is in the right storage for performance and access needs.
What are the benefits of a storage agnostic approach to unstructured data management?
- Freedom from Vendor Lock-in: You can classify, move, and access data without being forced into a single storage ecosystem. This enables negotiating power with storage vendors since your data workflows aren’t locked into proprietary formats or APIs.
- Unified Visibility Across Hybrid/Multi-Cloud: Provides a single pane of glass across NAS, object stores, and cloud tiers. IT and data teams can analyze usage, growth, and cost regardless of where the data resides.
- Consistent Policies and Governance: Apply the same classification, tagging, and retention rules across heterogeneous storage environments. This ensures compliance frameworks (e.g., GDPR, HIPAA) are met no matter where the data is stored.
- Optimized Data Placement for Cost and Performance: Move data across tiers or vendors based on actual usage patterns, not storage vendor constraints. Save costs by tiering cold data to cheaper platforms without breaking access.
- Faster AI and Analytics Enablement: Curate and deliver datasets from anywhere, without first consolidating into one vendor’s system.. Researchers and data scientists can access data in native format across different environments.
- Business Continuity and Flexibility: Easier cloud migrations, consolidations, or divestitures since you’re not tied to one platform.. Supports changing business priorities. (e.g., moving workloads from on-prem to Azure or AWS, without rearchitecting)
- Future-Proofing: As new storage technologies and cloud services emerge, you can integrate them without disrupting existing workflows. This reduces technical debt because your data management layer is portable.
The biggest takeaway: storage-agnostic UDM separates “data value” from “data storage.” That means organizations manage data for its business impact (cost, compliance, AI readiness) instead of being limited by where it happens to be stored.
Learn more about Komprise storage-agnostic unstructured data management.