Komprise Deep Analytics
Finding just the right data across billions of files is not easy.
Komprise Deep Analytics enables you to search and find the right unstructured data set that fits your specific criteria across hybrid storage.
Use the search results as the Global Metadatabase to both plan your unstructured data management strategy, automated transparent tiering and to enable new uses like sensitive data management, intelligent AI ingestion and feeding the right data to data lakes and data lakehouses.
What is Komprise Deep Analytics?
Enterprise IT organizations want to leverage unstructured data for new uses such AI ingestion and big data analytics, or to run applications in the cloud. But to get to AI readiness, data lakehouse quality and data science, you first need the right data. Studies show that 80% of the time in modern analytics and AI is spent on finding the right data and getting it out of data centers across hybrid data storage, archives and backups.
Komprise Deep Analytics addresses this problem by enabling customers to find the right data that fits specific criteria across all their storage and take action on these queries with Deep Analytics Actions and Smart Data Workflows. Komprise Deep Analytics searches the Komprise Global Metadatabase to find, classify, and act on exactly the right unstructured data sets across your entire storage estate — enabling precise AI data curation, intelligent tiering, and automated governance at petabyte scale. Komprise Deep Analytics creates a highly efficient, searchable distributed index with support for both standard metadata and custom metadata (tags). Customers can find data that fits criteria they set, regardless of where the data actually lives, and the resulting data set can be operated on as a discrete entity.
How Komprise Deep Analytics Fits
Komprise and industry research have shown that over 75% of data is infrequently accessed (cold) within months of creation. 80% of the cost of data is in its management; efficiently identifying and managing cold data yields significant savings. But in most organizations, both hot and cold data are being stored, replicated, and backed-up (usually multiple times) on expensive Tier 1 storage. Yet, organizations need to be as efficient as possible with their storage spend, especially given flat or shrinking IT budgets.
Komprise Intelligent Data Management software quickly identifies cold data across a customer’s NAS. Users can then move it to more cost-effective storage options, without any impact to users or applications, using the patented Komprise Transparent Move Technology (TMT™). This approach ensures that only active data is kept on expensive tier-1 primary storage.
Deep Analytics further extends the powerful analytics that Komprise already provides with a fully searchable index of all the data. This enables users to easily find specific data sets across storage, across billions of files. You can now search and find relevant data easily and with more granularity. Users can create custom queries to find the data, then tag them with custom tags to assemble virtual data lakes. For example, users can now create complex queries, find (and tag) specific projects, identify types of cold data, find orphan data, search for data owned by specific users, and more. It enables new uses of the data, such as for big data analytics and AI/ML applications.

Use Cases for Deep Analytics
 When you setup Komprise, within minutes, even on petabytes of data, you get a quick view of how data is growing, how data is being used, how much cold data you have, and your estimated ROI based on different scenarios
When you setup Komprise, within minutes, even on petabytes of data, you get a quick view of how data is growing, how data is being used, how much cold data you have, and your estimated ROI based on different scenarios
that help you plan your data management strategies. Analytics drives Komprise data management and analysis is available throughout the product, including under the Plan → Data and Plan → Usage tabs.
Deep Analytics is a query engine that enables users to perform deeper analysis at the file level, using custom queries and filters analysis for specific data sets within or across shares. This enables storage IT administrators to gain deeper insights about, and therefore greater control over, their enterprise’s data.
Deep Analytics creates a searchable index of all the standard metadata as well as extended metadata (or tags) of data across storage. Currently, all data sources analyzed by Komprise are also indexed by Deep Analytics when it is enabled.
With Deep Analytics, users can create custom queries using any combination of file metadata to narrow down to specific data sets, and can download reports including a summary as well as more detailed results. In addition, users can also summarize results by file metadata parameters.

Here are few examples of such queries:
- Find top users in the engineering department who have the largest amount of data on file server “NAS92”
- Find out which departments are creating large video and archive files across all shares
- Find out which users in R&D have not accessed most of their data in the last two years
- Find data of users who are no longer employed in the company

How Deep Analytics Works

Deep Analytics is a licensed feature, so it first must be specified in your license. Once licensed, there will be a setting to enable or disable Deep Analytics.
When shares are added to Komprise and enabled, Komprise starts to rapidly aggregate analytics information across these shares and these results are available in the Plan page. If Deep Analytics is enabled, then in the background, Komprise builds the Deep Analytics index. Deep Analytics runs take longer than the regular fast analysis, since every file’s metadata is examined and indexed.
After a Deep Analytics run has begun on a share, queries can be made against data (files) on that share. Query results, however, will be partial until the Deep Analytics run has completed on the share. Subsequent Deep Analytics runs will occur on each enabled share after a default delay interval of 28 days.
Deep Analytics keeps an index of all the standard and extended metadata. No file contents are stored. Indexed metadata includes:
- File name
- File parent directory
- File size
- File extension
- File type (directory, file, symbolic link, Komprise file link)
- File creation date
- File last modified date
- File last accessed date
- Owner id (uid/sid)
- Owner name
- Group id (uid/gid)
- Group name
- Tags (custom Komprise metadata)
NOTE: No file content is ever read or stored by Komprise.
Deep Analytics Tagging
Komprise Deep Analytics enables data to be tagged and for tags to be used in queries.
Tagging makes it easy to organize and find data based on extended metadata attributes beyond the standard file metadata. This can be useful in many ways:
- Grouping together data that satisfies multiple criteria easily
- Creating tags outside of Komprise (e.g. tagging data at the source when you know more about the data), and leveraging the tags to search and find relevant data within Komprise
- Managing and finding data by these tags rather than relying on just standard file metadata.
Example: Let’s say we want to run an operation on data belonging to either Project X or Project Y. We can first run a search in Komprise for any files that belong to Project X and tag them with Project X. Then similarly find and tag files related to Project Y. Then run another search in Deep Analytics for files with either Project X or Project Y tags and operate on that data set.
Tags can also be set via API outside of Komprise. Read: Automated Data Tagging with Komprise.
Deep Analytics API
All Deep Analytics functionality is accessible through an API. The API enables capabilities including:
- Creating, saving, renaming, deleting, and running queries
- Setting query filters on:
- File servers and shares
- Directory path
- File name
- Last modified time
- Last access time
- File type
- File extension
- File size
- Group
- Owner
- Tag
- Creating tags (keys and values)
- Applying and removing tags from files and query results
- Monitoring tagging tasks
- Retrieving the set of all tags (keys and values) created
- Summary of query results
- Top 5000 files of a query result
- Retrieving summary of query result by:
- Top shares
- Top file servers
- Top owners
- Top groups
- File types
- File extensions
- File sizes
- And retrieving the top 5000 files for any of these
Deep Analytics Deployment Architecture
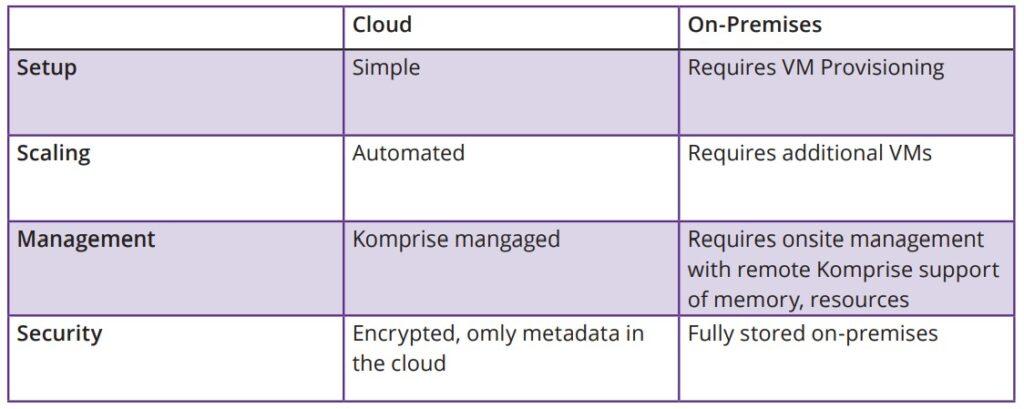
Deep Analytics utilizes secure, cloud-based services, including metadata indexes, and a powerful, open source analytics and search engine. No Deep Analytics components need to be deployed on-premises and the current Komprise Observers used in the Komprise Intelligent Data Management solution now also send file metadata into the secure cloud indexes.
When deployed in the cloud, Komprise manages all the analytics components in the cloud and the customer needs to only deploy on-premises Observers. This deployment is shown in Figure 4 below.
Advantages of a cloud-based deployment include:
- Fast, easy deployment, SaaS model: only standard Komprise Observers need to be deployed on-premises
- Enables use of thin Observer resources: simpler and cost-effective provisioning, maintenance, and growth accommodation
- Accommodates elastic growth and shrinking of data sizes: you can add more data to analyze or remove data and Komprise automatically adjusts so you don’t have to worry
- Enables transparent upgrades: only cloudbased components need to upgrade
When Deep Analytics is deployed on-premises, the customer is responsible for deploying the appropriate hardware for all components, as well as the Director, Observers, Analytics Services, Search Cluster.

Komprise provides guidelines for requirements of server sizing and software. In both cases, Komprise ensures a secure, scalable, high performance system deployment.

FAQs and Next Steps
What is Komprise Deep Analytics and how does it turn a petabyte-scale data estate from a storage cost problem into a queryable, actionable intelligence layer?
Komprise Deep Analytics creates a highly efficient, searchable distributed index of unstructured data with support for both standard metadata and custom metadata; customers can find data that fits criteria they set, regardless of where the data actually lives, and the resulting data set can be operated on as a discrete entity. The significance of this capability is best understood by contrasting it with the alternative: billions of files scattered across dozens of NAS systems and cloud environments with no unified index, no way to query across silos, and no mechanism to identify specific datasets without manually searching each storage system:
- Deep Analytics is the query engine that runs on the Global Metadatabase — Komprise Deep Analytics powers precise data discovery by enabling custom metadata queries and tagging to curate targeted datasets; these curated sets can feed AI and ML pipelines and analytics workflows, automate policy-driven actions with Smart Data Workflows, and help deliver the right data to the right destinations for improved accuracy, governance, and ROI; the Global Metadatabase is the continuously updated index; Deep Analytics is the query interface through which that index becomes actionable
- Queries span standard and custom metadata simultaneously — users can create custom queries using any combination of file metadata to narrow down to specific data sets; a single Deep Analytics query can combine file age, file type, owner, department, project tag, sensitivity status, path, extension, and any custom metadata attribute extracted by KAPPA data services; this multi-dimensional query capability is what reduces millions of files to exactly the right cohort for a tiering policy, a compliance review, or an AI data pipeline
- The Global Metadatabase is delivered as a managed SaaS service — Komprise is delivered as a software as a service solution; for the Global Metadatabase, there is no database to install and no infrastructure to manage; IT teams gain petabyte-scale metadata intelligence without a database engineering project, without dedicated infrastructure, and without ongoing maintenance; the index is populated automatically as Komprise Observers connect to each storage source
- Deep Analytics is available in Komprise Intelligent Data Management — unlike Komprise Analysis, which provides aggregate storage analytics and reporting, Deep Analytics delivers file-level queryability across the full Global Metadatabase; this file-level intelligence is the foundation for Smart Data Workflows, AI data curation, sensitive data governance, and the precise tiering policies that capture the full cold data savings opportunity rather than applying blanket age-based rules
- The intelligence layer that no storage vendor can provide — storage-vendor analytics tools see only the storage they manage; Deep Analytics sees the entire enterprise data estate simultaneously, regardless of vendor; Komprise is storage-agnostic, giving organizations complete visibility and control over unstructured data across any NAS, cloud, or SaaS platform without locking data to proprietary environments; this cross-silo intelligence is the architectural prerequisite for every data management decision that actually reflects the full enterprise data estate
How does data classification and tagging through Deep Analytics transform unstructured data from invisible files into governed, AI-ready assets?
Most enterprise unstructured data has one layer of context: its filename and directory path. For the vast majority of files, that context is meaningless to any automated system — an AI pipeline, a governance tool, or a cost optimization policy cannot distinguish a confidential legal contract from an outdated marketing brief based on filename alone. Data classification and tagging through Komprise Deep Analytics adds the layer of structured context that makes unstructured data manageable, governable, and AI-usable:
- Automatic indexing is the starting point — when Komprise points at different file and object repositories, it automatically indexes all standard metadata and creates an unstructured data index, capturing file names, types, sizes, owners, creation and access dates, and directory structures across every silo; this automatic baseline classification happens without any IT configuration — the Global Metadatabase begins populating immediately when Observers connect to storage sources
- Enriched tagging extends classification to business context — all tags applied through Komprise Deep Analytics queries, KAPPA functions, third-party AI services, or direct API calls are written back to the Global Metadatabase and persist regardless of where the underlying file moves; a file tagged as “Project Alpha — Phase 2 — Confidential” retains that tag whether it lives on NetApp, has been tiered to AWS S3, or has been migrated to Azure NetApp Files; the classification travels with the data across its full lifecycle
- Self-service tagging empowers data owners without burdening IT — Komprise automatically discovers and classifies all unstructured data indexed into the Global Metadatabase; Komprise provides built-in scanners to extend this with header metadata, multi-modal metadata, sensitivity tags, and provides an extensible approach to integrating any custom function to tag data; researchers, legal teams, and department heads can tag their own data through the Deep Analytics interface, participating in classification without requiring IT to mediate every tagging action
- Tags at the edge before data moves to cloud deliver faster AI results — tagging data at the edge, before it moves to the cloud, delivers faster AI results, lower egress costs, and better data quality at the destination; it is also the only practical approach for datasets where full-file movement is cost-prohibitive; network restrictions including limited bandwidth, long latency, and costs can make sending massive datasets over the internet problematic; searching and narrowing just the right data before sending it to the cloud can speed up data analytics significantly; classification before movement is the principle that makes AI data preparation economically viable at petabyte scale
- KAPPA data services extend classification to formats standard tools cannot read — KAPPA data services extract custom, domain-specific metadata from proprietary file formats at petabyte scale using serverless processing; DICOM headers, genomics BAM file attributes, FASTQ sequencing metadata, and ERP project codes are extracted with a few lines of Python and written as searchable tags to the Global Metadatabase; by combining rich metadata with powerful search via Deep Analytics and policy-driven Smart Data Workflows, the Komprise Global Metadatabase lets you select exactly the right files to feed into AI or vector embedding pipelines while excluding sensitive or irrelevant data; this means better AI precision, lower compute costs, and stronger data governance
How does a Deep Analytics query become a Smart Data Workflow — and why is that connection the key to automating AI data preparation at enterprise scale?
Deep Analytics identifies the right data. Smart Data Workflows act on it. The connection between the two is the mechanism that transforms a one-time query result into a continuously executing, policy-driven data pipeline that operates automatically as new data arrives and existing data ages:
- The query defines the dataset; the workflow automates what happens to it — the Global Metadatabase Service allows enterprise customers to find specific data sets and then create a data management policy or Smart Data Workflow to systematically take action on the data set; an IT team that runs a Deep Analytics query to find all genomics files from completed projects older than 18 months can turn that query directly into a Smart Data Workflow that continuously identifies new files meeting those criteria and automatically tiers them to lower-cost storage without any further manual intervention
- Smart Data Workflows automate the full AI data pipeline — Smart Data Workflows take Deep Analytics Actions a step further by allowing IT users and storage admins to create automated workflows for all the steps required to find the right unstructured data across storage assets, tag and enrich the data, and send it to external tools for analysis; a single Smart Data Workflow can chain KAPPA metadata extraction, sensitive data exclusion, format conversion, and delivery to an AI service as a continuous, governed, automated pipeline that runs without manual curation on each cycle
- The no-code workflow editor makes AI data pipelines accessible — Komprise Smart Data Workflows are configured through an intuitive workflow editor that does not require scripting or engineering resources; IT teams can define the Deep Analytics query criteria, the enrichment steps, the sensitivity exclusions, and the delivery destination in a visual interface; whether you are trying to feed the right data to AI or using AI to process data and tag the results, you can set up any of these workflows in Komprise by finding the data you want using queries, then setting the AI destination, and defining the frequency at which you want Komprise to send new data; AI data pipelines that previously required weeks of engineering effort are configured in hours
- Audit trails make every workflow action governance-compliant — Komprise does not only maintain security and access control of your data, but it also keeps an audit log of all data movement; this ensures you have audit trails of what data was fed to AI, when, and by whom for data governance; every Deep Analytics query, every tag applied, and every file delivered through a Smart Data Workflow is logged with complete lineage; when a HIPAA audit or AI governance review requires demonstrating what data was used in a model, Komprise provides the complete, tamper-proof record
- Komprise is the metadata and orchestration layer for enterprise unstructured AI data — the Deep Analytics to Smart Data Workflow pipeline is the operational expression of that positioning; Deep Analytics provides the intelligence to identify exactly the right data; Smart Data Workflows provide the orchestration to act on that intelligence continuously, automatically, and with governance at every step; this is what makes petabyte-scale AI data preparation a repeatable operational capability rather than a one-time engineering project
Why do organizations that invest in data classification today gain a compounding AI advantage over those that defer it — and how does Komprise Deep Analytics accelerate the classification journey?
Unstructured data classification is widely acknowledged as essential for AI data preparation, sensitive data governance, and storage cost optimization. The reason most organizations have not done it comprehensively is the same reason they have not tiered their cold data: without the right tooling, classification at petabyte scale requires more manual effort than any IT team can sustain. The consequence of deferring classification is compounding:
- Every unclassified file is a governance liability and an AI liability simultaneously — unclassified unstructured data cannot be governed for sensitive content before AI ingestion, cannot be precisely curated for a specific AI use case, and cannot be confidently tiered without risking the movement of data that should remain accessible or protected; the Komprise 2026 State of Unstructured Data Management survey found that classifying and tagging unstructured data is the top challenge in prepping data for AI at 56% of organizations — larger than any other challenge; the organizations that begin classification now are building the metadata foundation that every subsequent AI initiative will depend on
- Classification compounds in value with each new AI use case — a genomics organization that classifies its BAM and FASTQ files by instrument, run date, cohort, and sensitivity status does that work once; every subsequent AI project that needs sequencing data from a specific instrument platform or clinical cohort queries the Global Metadatabase and finds precisely the right dataset in seconds; the classification investment is amortized across every AI use case that follows, compounding in value indefinitely
- Deep Analytics makes classification faster through query-driven automation — with Deep Analytics, users can create complex queries, find and tag specific projects, identify types of cold data, find orphan data, search for data owned by specific users, and more; rather than manually reviewing files one by one, IT teams run queries that identify large populations of files meeting specific criteria and apply classification tags to the entire population simultaneously; a query that finds all files in a specific directory path, of a specific type, modified in a specific date range can tag thousands of files in a single operation
- The cost optimization case for classification reinforces the AI case — the same classification that makes data AI-ready also makes cold data identification precise rather than approximate; a tiering policy that can distinguish cold project data from cold regulatory data from cold AI training data applies appropriately different lifecycle rules to each; organizations that defer classification apply blunt age-based tiering policies that move the wrong data, miss the right data, and generate user complaints that slow the entire tiering program; precise classification is what makes intelligent tiering actually intelligent
- Flash prices make the cost of deferred classification visible in budget terms — TrendForce projects NAND Flash contract prices to rise sharply through the current pricing cycle, with meaningful capacity expansion unlikely for at least two to three years; the cold data sitting on expensive flash that has never been classified cannot be confidently tiered because IT does not know what it is; the Komprise Flash Stretch Assessment for qualified enterprises managing 500TB or more reveals exactly how much classifiable cold data is consuming premium flash storage and models the savings from classifying and tiering it — making the cost of deferred classification specific and measurable
How does Komprise Deep Analytics address the challenge of finding and acting on sensitive data across a petabyte-scale unstructured data estate before it reaches AI tools?
The connection between data classification, sensitive data governance, and AI risk is one of the most consequential operational challenges enterprise IT teams face. Komprise eliminates the clutter and noise inherent in unstructured data; Komprise Deep Analytics enables you to search across the entire Global Metadatabase to find just the right data for each AI use case; that same capability — finding exactly the right data — also means finding exactly the wrong data before it reaches AI tools:
- Sensitive data detection is built into the classification layer — Komprise automatically classifies all unstructured data and builds a Global Metadatabase; in addition to helping curate and find the right data, Komprise makes this actionable since you can create workflows using the curated data sets with Komprise Smart Data Workflows Manager; sensitive data detection is also built in; PII and PHI scanners, custom regex, and keyword search operate across the full Global Metadatabase simultaneously, flagging sensitive content at the metadata layer rather than requiring file-by-file inspection
- Deep Analytics queries identify sensitive data across all silos at once — a single Deep Analytics query can find all files containing specific PII patterns, all DICOM files with embedded patient identifiers, or all documents matching legal hold criteria across every NAS, cloud, and object storage environment simultaneously; this cross-silo sensitive data identification is what makes comprehensive governance practical rather than aspirational at petabyte scale
- Smart Data Workflows automate remediation after identification — once Deep Analytics identifies sensitive data, a Smart Data Workflow can automatically confine it to a protected storage tier, exclude it from AI pipelines, flag it for review, or apply a legal hold tag — all without IT manually processing each identified file; the governance action is as automated as the governance discovery
- Tags persist through the AI lifecycle — Komprise applies all tags back to the Global Metadatabase even when a cached copy is used for AI, ensuring the original data is continuously enriched and governance records remain current; a file tagged as sensitive in the Global Metadatabase retains that tag through every subsequent data movement, tiering action, and AI workflow; the sensitivity classification is not a point-in-time scan result — it is a persistent governance attribute that follows the data wherever it goes
- The governance case and the AI data quality case are identical — filter out noisy, poor-quality data to improve AI accuracy by over 50%; detect and handle sensitive data; removing sensitive data from AI pipelines is simultaneously a governance action and an accuracy improvement; a model that trains on properly governed, sensitivity-excluded data produces better outputs than one trained on everything including PHI, outdated files, and confidential IP; Komprise Deep Analytics and Smart Data Workflows make governance and AI quality the same operational motion rather than competing priorities that require separate tooling
- Learn more about the Komprise Global Metadatabase
- Learn more about Komprise Deep Analytics Actions.
- To see Deep Analytics in your environment, schedule a demonstration.