Data Management Glossary
AI Data Management

What is AI Data Management?
AI Data Management is the discipline of discovering, enriching, governing, curating and delivering enterprise data so AI systems can securely retrieve accurate, current and relevant information. Unlike traditional data management, AI data management emphasizes metadata, context, governance and continuous data preparation rather than simply storing data. It covers the full lifecycle: from identifying which data exists and where it lives, to ensuring only relevant, high-quality, governed data reaches an AI pipeline.
Unstructured data is the fuel for AI. Files, documents, images, video, sensor logs, genomics outputs, and engineering drawings make up 85% of enterprise data and the majority of what foundation models and generative AI require. More than 80% of enterprise data is unstructured, but less than 1% is typically available to AI, according to IBM. AI data management bridges this gap by making unstructured enterprise data discoverable, trustworthy and consumable without requiring organizations to copy or move petabytes of files.
- Finding and curating the right data
- Moving and preparing data for AI pipelines
- Ensuring data is high-quality, compliant, and properly tagged (see data tagging)
- Optimizing where data is stored and how it’s accessed
- Tracking data lineage and governance for responsible AI
What is the Role of Unstructured Data in AI Data Management?
- LLMs → text, emails, reports
- Multimodal AI → images + text + video
- AI search & retrieval → documents, PDFs, data lakes
- AI-powered compliance → identifying sensitive files and preventing AI data leakage
So, managing unstructured data is critical to making enterprise AI effective.The challenge is not just volume. It is visibility. Most enterprise unstructured data sits across dozens of NAS systems, cloud environments, and object stores with no consistent index, no cross-silo search, and no native mechanism for classification. According to the Komprise 2026 State of Unstructured Data Management report, classifying and tagging unstructured data is the top challenge in preparing data for AI, cited by 56% of IT and storage leaders, up from 41% in 2024. And according to the Informatica CDO Insights 2025 survey of 600 global data leaders, 43% cite data completeness, quality, and readiness as the leading obstacle
blocking AI initiatives from reaching production.
Metadata is the foundation of AI Data Management
Modern AI systems cannot efficiently work directly against billions of enterprise files. Instead, they rely on metadata that describes those files. The Komprise Global Metadatabase creates a continuously updated metadata layer across NAS, object storage and cloud environments, enabling discovery, governance, search and AI data preparation at enterprise scale.
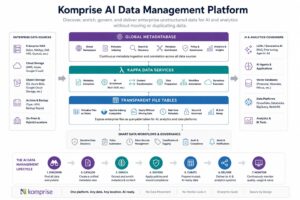
Komprise for AI Data Management
Komprise helps enterprises manage and prepare unstructured data for AI. Unstructured data is the fuel for AI, and most enterprises (74%) are now storing more than 5PB of it, a 57% increase over 2024, according to the Komprise 2026 State of Unstructured Data Management report. Here are some examples of Komprise AI data management:

Data Discovery & Curation
The Komprise Global Metadatabase catalogs unstructured data across NAS, cloud, and object storage silos without moving the underlying data. It is the metadata intelligence layer that makes unstructured data discoverable, classifiable, and queryable across all storage environments simultaneously. Find and classify relevant data for AI projects. Tags and enriches data so AI models can understand it.
Data Mobility & Preparation
Komprise Intelligent AI Ingest curates and routes the right file and object data to AI-friendly environments including cloud object stores and data lakes, without replicating data unnecessarily. Only high-value, relevant data reaches the AI pipeline, which reduces compute costs and eliminates noise.
Data Tiering & AI Cost Optimization
Komprise customers optimize data storage by keeping hot AI data on fast, high-performance storage while moving cold data to lower-cost storage tiers. This approach saves on data storage costs and cloud egress costs, which can explode in AI pipelines.
SQL Access for Data Engineering Teams
Transparent File Tables surface Global Metadatabase content as SQL-queryable virtual tables, giving data engineering and analytics teams direct access to file metadata alongside structured data in platforms like Databricks and Snowflake. No file copying, no custom extraction pipelines required.
Governance & Compliance
Komprise helps track data lineage (where data came from, how it was transformed), which is essential for trustworthy and auditable AI. Smart Data Workflows identify and protect sensitive data in AI pipelines, including PII and IP.
To summarize, without Komprise unstructured data is siloed, hard to find or move. With Komprise, unstructured data is cataloged and easy to curate for AI. Without Komprise Intelligent Data Management, AI pipelines waste GPU compute on noisy, irrelevant, or duplicate files. With Komprise you get only relevant, high-value data. Komprise delivers automated,
optimized data workflows with clear governance, tagging, and lineage tracking.

AI Data Ingestion
AI data ingestion is the process of discovering, collecting, and delivering data into AI and machine learning pipelines for training, inference, or retrieval-augmented generation (RAG).It often includes pulling data from file storage, object storage, cloud repositories, and enterprise systems.
Why it matters:
AI outcomes depend on having access to the right data. Without efficient ingestion, projects stall due to fragmented storage, poor visibility, and slow data access.
How Komprise helps:
Komprise Intelligent AI Ingest provides a global view of unstructured data across all storage
silos, helping organizations quickly identify, curate, and deliver the right data to AI
initiatives without manual pipeline engineering or unnecessary data replication.
AI Data Preparation
AI data preparation is the process of cleaning, organizing, enriching, and filtering data before it is used by AI models. This includes removing duplicates, classifying files, adding metadata, and selecting relevant datasets.
Why it matters:
Poor-quality data leads to poor AI results. Effective preparation improves model accuracy, speeds training, and reduces wasted compute resources.
How Komprise helps:
The Komprise Global Metadatabase indexes standard and custom metadata across all storage environments, making it possible to identify valuable datasets, eliminate stale or redundant files, detect sensitive data, and automate workflows that make unstructured data AI-ready at petabyte scale.
Unstructured Data for AI
Unstructured data includes documents, images, videos, emails, PDFs, and logs. It represents the majority of enterprise data and contains valuable business knowledge, customer insights, and operational context that AI models need to produce relevant, accurate outputs. According to Gartner, 80 to 90% of all new enterprise data is unstructured, and it is growing three times faster than structured data.
Why it matters:
Modern AI models and generative AI systems rely heavily on unstructured data to improve relevance, accuracy, and business context. Without it, AI operates on an incomplete picture of the enterprise. According to the Komprise 2026 State of Unstructured Data Management report, classifying and tagging unstructured data is the top challenge in preparing data for AI, cited by 56% of IT and storage leaders.
How Komprise helps:
The Komprise Global Metadatabase indexes file and object data across every storage silo, making it possible to identify, classify, and route the right unstructured data to AI pipelines with governance applied and without manual effort. KAPPA data services extend that capability to proprietary and domain-specific file formats including DICOM medical images, genomics BAM files, and engineering drawings, extracting custom metadata that standard indexing tools cannot reach.
RAG Pipelines
A retrieval-augmented generation (RAG) pipeline combines AI models with enterprise data retrieval. Instead of relying only on model training, it retrieves relevant documents or files in real time and uses them to generate more accurate, grounded responses.
Why it matters:
RAG improves AI accuracy, reduces hallucinations, and keeps answers grounded in current enterprise data. The quality of RAG output depends entirely on the quality of the retrieval index feeding it.
How Komprise helps:
Komprise powers RAG pipelines by indexing unstructured data across all storage environments through the Global Metadatabase, enabling fast search and precise metadata filtering to surface the most relevant enterprise content. Deep Analytics queries the Global Metadatabase to produce curated, governed datasets that feed RAG pipelines with high-signal content rather than raw file dumps, reducing noise and improving retrieval accuracy.
AI Cost Optimization
AI cost optimization is the practice of reducing the infrastructure, storage, and compute costs associated with AI workloads while maintaining performance and outcomes.
Why it matters:
AI projects can become expensive due to GPU demand, storage growth, data movement, and inefficient pipelines. Controlling costs is essential for scaling AI successfully. Nearly all organizations (85%) will spend more on data storage and backups in 2026, up from 59% in 2024, according to the Komprise 2026 State of Unstructured Data Management report.
How Komprise helps:
Komprise lowers AI costs by identifying and tiering inactive data off expensive primary storage, reducing unnecessary data movement across environments, and ensuring only relevant, high-value data enters AI workflows. Customers consistently achieve 70% or more reductions in primary storage and backup costs while keeping hot AI data on fast, high-performance storage where it is needed.
| Without storage-agnostic unstructured data management | With Komprise | |
|---|---|---|
| Discover: Index all unstructured data across every silo | ✗Unstructured data is siloed across NAS, cloud, and object storage with no cross-silo index. There is no single view of what data exists, where it lives, or whether it is relevant to any AI project. | ✓The Global Metadatabase continuously indexes metadata across all storage environments simultaneously. Every file across every silo is discoverable in a single query, regardless of vendor or location. |
| Understand: Make it queryable by metadata and context | ✗Files cannot be searched by content, context, or custom attributes across storage vendors. Classification is manual and impossible to enforce at petabyte scale, leaving AI pipelines with no reliable way to filter signal from noise. | ✓Deep Analytics queries the Global Metadatabase by both system metadata and custom tags across billions of files with consistent performance. Any file can be found, filtered, and acted on based on precise criteria rather than manual selection. |
| Enrich: Apply the domain attributes AI needs | ✗Standard indexing tools cannot parse proprietary or domain-specific file formats including DICOM medical images, genomics BAM files, engineering drawings, and ERP exports. Valuable domain data stays opaque and out of reach for AI use cases. | ✓KAPPA data services extract custom metadata from any proprietary format using serverless Python and write those attributes back to the Global Metadatabase as searchable tags. Enriched metadata persists across the full file lifecycle, even after tiering or migration. |
| Govern: Detect and control sensitive data before AI | ✗PII, IP, and regulated data enter AI pipelines undetected. No mechanism exists to identify sensitive content in files at scale before it reaches a model or external service, creating compliance exposure and security risk. | ✓Smart Data Workflows scan file content using 68 built-in PII scanners plus custom regex, scoped by a Deep Analytics query. Sensitive data is identified, tagged, and governed automatically before it reaches any AI pipeline. |
| Deliver: Send the right data to each AI pipeline | ✗AI models receive raw, unfiltered file dumps with no curation. GPU compute is wasted on noisy, irrelevant, outdated, or duplicate data. Cloud egress costs explode as pipelines move data without filtering, and there is no lineage record of what entered the pipeline or why. | ✓Komprise Intelligent AI Ingest curates and routes only high-value, relevant data to each AI pipeline without unnecessary replication. Data lineage is tracked across the full lifecycle, making every pipeline auditable, trustworthy, and compliant by design. |
| Cost Savings: Storage and compute efficiency | ✗60-70% of NAS data sits cold on expensive primary storage because IT teams lack the metadata context to classify and move it safely. Without curation, AI workloads drive cloud egress costs that scale with every pipeline run. | ✓Policy-based tiering driven by metadata queries automatically moves cold data to lower-cost storage while keeping hot AI data on high-performance tiers. Komprise customers consistently achieve 70% or more reductions in primary storage and backup costs. |

More AI Data Management FAQs
How does unstructured data management affect inferencing costs in production AI systems?
Poor unstructured data management drives up inferencing costs in two ways. First, when AI pipelines ingest redundant, low-quality, or irrelevant file data, models process more tokens per query than necessary, increasing compute cost per inference. Second, when data is stored on high-cost primary flash or cloud object storage without lifecycle policies, the retrieval and egress costs of serving that data to inferencing workloads compound over time. Komprise addresses both by curating only relevant, high-value unstructured data for AI pipelines through Smart Data Workflows, and by keeping hot AI data on fast storage while automatically tiering cold data to lower-cost tiers, reducing the total cost of running production AI systems at enterprise scale.
How does Komprise support AI data management for agentic AI workflows?
Agentic AI systems need to autonomously discover, retrieve and act on enterprise data across distributed storage environments. This requires a metadata layer rich enough to make unstructured data findable by context, not just filename or path. Komprise supports agentic AI workflows through the Global Metadatabase, which maintains a continuously updated, vendor-neutral catalog of file and object data across hybrid storage environments. Agents can query this catalog to locate relevant data, trigger Smart Data Workflows to move or copy it to the right destination, and use KAPPA to extract and enrich custom metadata before data enters an AI pipeline. This gives agentic systems governed, auditable access to enterprise unstructured data without requiring manual curation at every step.

What is the difference between AI data management and traditional data management for unstructured data?
Traditional unstructured data management focuses primarily on storage cost reduction, capacity planning, and lifecycle policies — moving cold data off primary NAS to lower-cost tiers. AI data management extends this foundation to include data quality, metadata enrichment, and governed curation for AI pipelines. Where traditional data management asks where data should live and what it costs, AI data management also asks whether data is accurate, relevant, and properly tagged for the AI model or RAG pipeline consuming it. Komprise bridges both disciplines in a single platform, combining analytics-driven tiering and storage cost optimization with KAPPA metadata enrichment, Smart Data Workflows for AI ingestion, and the Global Metadatabase as a searchable, AI-queryable catalog across all unstructured data silos.
What is the difference between AI data management and traditional data management?
Traditional data management focuses on organizing, storing, and retrieving data for business operations and analytics. AI data management adds requirements specific to AI pipelines: data must be classified by quality and relevance, enriched with metadata, filtered to remove noise and duplicates, governed to prevent sensitive data leakage, and delivered to AI systems in formats they can consume. For unstructured data specifically, this requires a metadata intelligence layer that does not exist in traditional storage or data management platforms.
What role does metadata play in AI data management?
Metadata is the control layer for AI data management. Without it, you cannot identify which files are relevant to a specific AI use case, which are outdated or duplicated, which contain sensitive data that should not enter a training set, or which are cold and wasting expensive primary storage. The Komprise Global Metadatabase indexes standard and custom metadata across all storage silos, making it possible to classify, filter, and route unstructured data to AI pipelines based on precise criteria rather than manual selection.
How does AI data management connect to RAG pipelines?
Retrieval-augmented generation (RAG) pipelines retrieve relevant context from enterprise data to ground AI model responses. The quality of RAG output depends entirely on the quality of the retrieval index feeding it. Metadata intelligence is what makes that index precise: it identifies which documents are current, authoritative, and relevant to a given query domain, and filters out stale, duplicate, or irrelevant content before it enters the retrieval layer. Komprise Deep Analytics queries the Global Metadatabase to produce curated, governed datasets that feed RAG pipelines with high-signal content rather than raw file dumps.
How is AI data management different from a data catalog?
A data catalog documents what data exists and helps analysts find it. AI data management goes further: it classifies and enriches data, enforces governance policies, moves or routes data automatically based on metadata criteria, and delivers curated datasets to AI systems without manual intervention. A catalog answers “what do we have?” AI data management answers “what should go to the AI pipeline, in what form, with what governance applied, and at what cost?”
What is metadata intelligence, and why does it matter for AI data management?
Metadata intelligence is the practice of collecting, enriching, and activating metadata to drive automated decisions across the data estate. For AI data management, it is the foundation: without knowing what a file contains, how old it is, who owns it, whether it has been accessed recently, and whether it contains sensitive data, it is impossible to make reliable decisions about what to include in an AI pipeline. Komprise delivers metadata intelligence through the Global Metadatabase, KAPPA data services for custom metadata extraction from proprietary file formats, and Deep Analytics for real-time query across billions of files. Visit the KAPPA data services library.