Data Management Glossary
Data Tiering
What is Data Tiering?
Data Tiering is the practice of moving less frequently used data, also known as cold data, to cheaper levels of storage or tiers. The term “data tiering” arose from moving data around different tiers or classes of storage within a storage system. It has now expanded to mean tiering or archiving data from a storage system to other clouds and storage systems. See also cloud tiering and choices for cloud data tiering.
Traditional data tiering relies on static policies (e.g., age-based movement), while modern approaches use analytics to determine actual data access patterns. The right approach to tiering reduces storage costs by placing infrequently-accessed data on lower-cost storage.
How this relates to Komprise?
Komprise uses analytics-driven data tiering to identify cold data and transparently move it to object storage while maintaining seamless user access. Unlike storage-native tiering, it works across heterogeneous environments and at file-level granularity.

Data Tiering Cuts Costs Because 70%+ of Data is Cold
As data grows, storage costs are escalating. It is easy to think the solution is more efficient storage. But the real cause of storage costs is poor data management. Over 70% of data is cold and has not been accessed in months, yet it sits on expensive storage and consumes the same backup resources as hot data. As a result, data storage costs are rising, backups are slow, recovery is unreliable, and the sheer bulk of this data makes it difficult to leverage new options like Flash and Cloud.
Data Tiering Was Initially Used within a Storage Array
Data Tiering was initially a technique used by storage systems to reduce the cost of data storage by tiering cold data within the storage array to cheaper but less performant options. For example, moving data that has not been touched in a year or more from an expensive Flash tier to a low-cost SATA disk tier.
Typical storage tiers within a storage array include:
- Flash or SSD: A high-performance storage class but also very expensive. Flash is usually used on smaller data sets that are being actively used and require the highest performance.
- SAS Disks: Usually the workhorse of a storage system, they are moderately good at performance but more expensive than SATA disks.
- SATA Disks: Usually the lowest price-point for disks but not as performant as SAS disks.
- Secondary Storage, often Object Storage: Usually a good choice for capacity storage – to store large volumes of cool data that is not as frequently accessed, at a much lower cost.

Cloud Data Tiering is now Popular
Increasingly, customers are looking at another option: tiering or archiving data to a public cloud.
- Public Cloud Storage: Public clouds currently have a mix of object and file storage options. The object storage classes such as Amazon S3 and Azure Blob (Azure Storage) provide tremendous cost efficiency and all the benefits of object storage without the headaches of setup and management.
Tiering and archiving less frequently used data or cold data to public cloud storage classes is now more popular. This is because customers can leverage the lower cost storage classes within the cloud to keep the cold data and promote them to the higher cost storage classes when needed.
For example, data can be archived or tiered from on-premises NAS to Amazon S3 Infrequent Access or Amazon Glacier for low ongoing costs, and then promoted to Amazon EFS or FSX when you want to operate on it and need performance.
But in order to get this level of flexibility, data that is tiered to the cloud needs to be accessible natively in the cloud without requiring third-party software. This requires file-tiering, not block-tiering.
Block Tiering Creates Unnecessary Costs and Lock-In
Block-level tiering was first introduced as a technique within a storage array to make the storage box more efficient by leveraging a mix of technologies such as more expensive SAS disks as well as cheaper SATA disks.
Block tiering breaks a file into various blocks: metadata blocks that contain information about the file, and data blocks that are chunks of the original file. Block-tiering moves less used cold blocks to lower, less expensive tiers. Meanwhile hot blocks and metadata are retained in the higher, faster, and more expensive storage tiers.
Block tiering is a technique used within the storage operating system or filesystem and is proprietary. Storage vendors offer block tiering as a way to reduce the cost of their storage environment. Many storage vendors are now expanding block tiering to move data to the public cloud or on-premises object storage.
But, since block tiering s done inside the storage operating system as a proprietary solution, it has several limitations when it comes to efficiency of reuse and efficiency of storage savings.
- Firstly, with block tiering, the proprietary storage filesystem must be involved in all data access since it retains the metadata and has the “map” to putting the file together from the various blocks.
- This also means that the cold blocks that are moved to a lower tier or the cloud cannot be directly accessed from the new location without involving the proprietary filesystem. This is because the cloud does not have the metadata map and the other data blocks and the file context and attributes to put the file together.
- So, block tiering is a proprietary approach that often results in unnecessary rehydration of the data and treats the cloud as a cheap storage locker rather than as a powerful way to use data when needed.
The only way to access data in the cloud is to run the proprietary storage filesystem in the cloud which adds to costs. Also, many third-party applications such as backup software that operate at a file level require the cold blocks to be brought back or rehydrated. This action defeats the purpose of tiering to a lower cost storage and erodes the potential savings. For more details, read the white paper: Block vs. File-Level Tiering and Archiving.
Know Your Cloud Tiering Choices

File Tiering Maximizes Savings and Eliminates Lock-In
Cost Effective File Tiering Services: File-tiering is an advanced modern technology that uses standard protocols to move the entire file along with its metadata in a non-proprietary fashion to the secondary tier or cloud. File tiering is harder to build but better for customers because it eliminates vendor lock-in and maximizes savings.
Whether files have POSIX-based Access Control Lists (ACLs) or NTFS extended attributes, all this metadata along with the file itself is fully tiered or archived to the secondary tier and stored in a non-proprietary format. This ensures that the entire data can be brought back as a file when needed.
File tiering does not just move the file, but it also moves the attributes and security permissions and ACLS along with the file. This maintains full file fidelity even when you are moving a file to a different storage architecture such as object storage or cloud. Therefore, applications and users can directly open the file natively in the secondary location or cloud without requiring any third-party software or storage operating system.
You can then maximize savings since backup software and other third party applications can access moved data without rehydrating or bringing the file back to the original location. As well, you can use the cloud to run valuable applications such as compliance search or big data analytics on the trove of tiered and archived data without incurring additional costs.
File-tiering is an advanced technique for archiving and cloud tiering that maximizes savings and breaks vendor lock-in. It’s time to adopt more cost-effective file tiering services and strategies that optimize data storage costs and unlock the potential of unstructured data in the enterprise.
Data Tiering Can Cut 70%+ Storage and Backup Costs When Done Right
In summary, data tiering is an efficient solution to cut storage and backup costs because it tiers or archives cold, unused files to a lower-cost storage class, either on-premises or in the cloud. However, to maximize the savings, data tiering needs to be done at the file level, not block level. Block-level tiering creates lock-in and erodes much of the cost savings because it requires unnecessary rehydration of the data. File tiering maximizes savings and preserves flexibility by enabling data to be used directly in the cloud without lock-in.
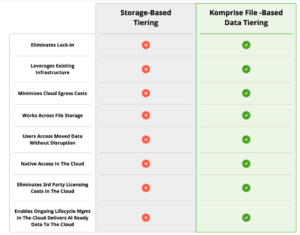
Why Data Tiering with Komprise Intelligent Data Management?
This chart summarizes the differences between storage-based tiering and Komprise file-based data tiering. Traditional tiering uses static rules, while intelligent tiering uses real usage analytics and users and apps retain transparent access even after data is moved.
Learn more about Komprise Transparent Move Technology.
Why Komprise is the easy, fast, no lock-in path to the cloud for file and object data.

How can intelligent data tiering help enterprises offset the surge in flash storage and NAND prices in 2026?
Gartner estimates DRAM and SSD prices will rise 130% by end of 2026, driven by AI infrastructure demand consuming memory supply at an unprecedented rate. For enterprises storing petabytes of unstructured data on all-flash NAS arrays, buying more capacity is not a viable response. Intelligent data tiering is the most effective way to reclaim capacity and offset the impact without a hardware purchase. Komprise Flash Stretch addresses this directly:
- Know before you tier — The Komprise Global Metadatabase indexes all unstructured data across every storage silo and shows exactly which files are cold, who owns them, how long since last access, and what they cost on primary flash, before any data is moved
- Reclaim 70%+ of primary flash capacity — many enterprises discover that 60% to 80% of file data is inactive but still consuming premium primary storage; Komprise intelligently identifies and tiers that cold data to lower-cost object storage or cloud transparently, freeing immediate headroom without disrupting users or applications
- No rehydration penalty — unlike storage-vendor tiering, Komprise cuts 70%+ of storage, backup, and ransomware defense costs and eliminates rehydration costs when switching vendors
- Compound savings across backup and DR — because Komprise moves entire files off primary storage, backup footprints shrink immediately, cutting backup licensing, DR replication, and disaster recovery costs alongside storage hardware costs
- Proven cost savings at scale — Pfizer reduced storage and cloud costs by 70 to 75% using Komprise intelligent tiering; a major hospital in the southeast is saving $2.5M per year by tiering cold files from on-premises storage to the cloud
- Built for data-heavy enterprises — Flash Stretch is designed for organizations managing 500TB or more of unstructured data across NAS and hybrid cloud environments, where the volume of cold data on expensive primary storage represents the single largest opportunity for immediate cost reduction
How does intelligent data tiering support enterprise AI initiatives and why is it a prerequisite for AI-ready infrastructure?
Intelligent data tiering and AI readiness are directly connected. The same all-flash NAS storage that AI training and inferencing workloads require is filled with cold, unanalyzed data that belongs on lower-cost tiers. Tiering cold data off primary storage does not just cut costs; it creates the governed, indexed, cloud-accessible data foundation that AI pipelines depend on. The Komprise connection:
- Frees primary storage for AI workloads — moving cold data off expensive flash NAS creates immediate headroom for the high-performance storage that active AI datasets and inference workloads actually require, without a hardware purchase or a budget increase
- Builds the Global Metadatabase — Komprise indexes all file metadata at the point of tiering, continuously enriching the Global Metadatabase with location, access patterns, file type, classification status, and sensitivity data; this creates the unified, queryable metadata foundation that Smart Data Workflows use to identify and curate AI-ready datasets across the full hybrid estate
- Cloud-native AI access — hybrid tiering ensures data is not locked in proprietary formats, making it accessible, searchable, and AI-ready with proper governance and compliance; data tiered to AWS S3, Azure Blob, or Google Cloud Storage is immediately available to cloud AI training, RAG pipelines, and analytics services in native format without a secondary migration or ETL step
- Filters AI pipeline noise — tiering cold, duplicate, and outdated files off primary storage before AI ingestion removes the data noise that degrades model accuracy; Komprise Smart Data Workflows can then operate on a cleaner, more relevant dataset, reducing GPU compute costs and improving AI output quality
- Ransomware defense as a byproduct — offloading cold files to immutable Azure Blob or S3 Object Lock removes cold files from the active attack surface, eliminating 80% of storage, DR, and backup costs while also providing a potential recovery path if cold files get infected
What is the difference between intelligent data tiering and built-in storage vendor tiering, and why does it matter for cost savings and AI?
Storage-vendor tiering is designed to optimize within a single vendor’s system. Intelligent data tiering is storage-agnostic and works across the entire hybrid enterprise data estate. The difference determines whether you save money once or continuously, and whether tiered data becomes an AI asset or a liability:
- Storage-agnostic vs. single-vendor — Komprise is vendor agnostic and can be deployed across most common storage arrays, allowing one consistent, global way to tier data with a single pane of glass across multi-vendor storage systems; storage-vendor tiering requires managing each cluster independently with no unified view
- File-level vs. block-level — file-level tiering ensures the entire file is archived as an object so it can be accessed natively in the cloud by any standard S3 tools without having to go back to the original file system or data management software; block-level vendor tiering stores proprietary blocks that require the originating storage OS to be running for access
- No rehydration vs. costly recalls — storage-vendor tiering immediately rehydrates data when accessed, requiring extra reserved storage capacity and generating unexpected egress fees during antivirus scans, defragmentation, and hardware refreshes; Komprise TMT streams data on demand and caches it locally without full rehydration
- AI-ready vs. locked away — data tiered by Komprise is written in native file and object formats, directly accessible to AI services at the cloud destination without additional ETL or migration; intelligent tiering helps free expensive high-performance storage for active AI workloads while making valuable unstructured data easier to identify, curate, and use in AI and analytics pipelines
- Proven cost advantage — in a 1PB scenario, Komprise hybrid tiering cut annual costs by 75% compared to storage-based tiering, reducing spend on storage, backup, and ransomware defense