Data Management Glossary
Global Metadatabase
What Is a Global Metadatabase?
A global metadatabase is a unified, cross-silo index of metadata that spans an organization’s entire unstructured data estate, regardless of which storage vendor, cloud provider, or location the underlying files actually live in. It is not a copy of your data. It is a continuously updated catalog of information about your data: file type, size, owner, creation and access dates, classification tags, and any custom attributes extracted from file content, all made queryable from a single interface.
The distinction between the Komprise Global Metadatabase and a traditional metadata catalog is architectural. Traditional catalogs are typically built for one storage system or one data type at a time, which means an organization with files spread across NAS systems, object stores, and multiple cloud providers ends up with a fragmented set of disconnected catalogs, none of which talk to each other. A global metadatabase indexes across all of those silos simultaneously, creating one queryable namespace for metadata regardless of where the files physically reside.
This matters because metadata, not the files themselves, is what makes data discoverable, governable, and usable for AI. A global metadatabase captures four categories of metadata: system metadata (name, size, type, dates), content metadata (information about what is inside the file), context metadata (how the file relates to other data and business processes), and custom metadata (domain-specific attributes extracted from proprietary formats). Together, these four categories transform a scattered file estate into a structured, analyzable asset.
Why a Global Metadatabase Is the Foundation for Enterprise AI
Unstructured data constitutes 70-90% of the enterprise data estate and is growing 40-60% per year, yet most organizations cannot answer basic questions about it: what exists, where it lives, who owns it, when it was last touched, or whether it is safe to use in an AI pipeline.
That visibility gap is the direct cause of the AI readiness crisis enterprises are facing right now. Only 14% of data leaders feel very confident their unstructured data is truly ready to power AI interactions, and 61% of data leaders report four to six separate document silos within their organization, a figure that covers documents alone and likely understates the true silo count once images, genomics data, engineering files, and other unstructured formats are included.
Source: Gartner Data Intelligence Monthly: Executive Insights on Unstructured Data for AI, May 2026 (ID G00853711, available via Gartner subscription)
A global metadatabase is the architectural answer to that gap. Every AI initiative, every governance program, and every storage cost optimization effort depends on first knowing what data exists and where. Without a unified metadata layer, each of those initiatives requires its own discovery process, repeated against the same fragmented storage estate, with no shared source of truth between them. With a global metadatabase, discovery happens once, continuously, and every downstream process, AI curation, sensitive data detection, tiering, analytics, queries the same authoritative index.
This is also why a global metadatabase is described as a control plane rather than a passive catalog. It is not simply a list of files. It is the layer that other systems query and act on. AI pipelines query it to curate datasets. Governance workflows query it to identify sensitive content. Analytics platforms query it to join unstructured file context with structured business data. The global metadatabase does not just describe the data estate; it is the mechanism that makes the data estate actionable.
Why Building and Maintaining a Global Metadatabase Is Difficult
Most organizations that attempt to build a unified metadata layer in-house run into the same three structural problems.
Data storage silos do not share a common metadata language. A NAS system, an S3-compatible object store, and a cloud-native file service each expose metadata differently, using different APIs, different field names, and different levels of detail. Building a unified index requires normalizing all of that into a consistent schema, a non-trivial engineering problem that scales in complexity with every additional storage vendor in the environment.
Proprietary file formats are invisible to standard indexing. A DICOM medical image, a genomics BAM file, an engineering CAD drawing, and an ERP export all carry valuable metadata inside their content, not just in their file system attributes. Standard indexing tools read file system metadata only; they cannot parse what is inside the file itself. Capturing that content metadata requires format-specific extraction logic for every proprietary type the organization uses, which is exactly the kind of specialized engineering work most IT teams do not have the bandwidth to build and maintain.
Indexing at petabyte scale without moving data is an unsolved problem for generic tools. Many approaches to building a unified catalog require copying or scanning the underlying files directly, which is slow, expensive, and operationally risky at the scale most enterprises operate at today. A global metadatabase has to index continuously, across billions of files, without disrupting production storage or requiring the files themselves to move.
How the Komprise Global Metadatabase Works
 The Komprise Global Metadatabase is a fully managed, distributed metadata catalog that continuously indexes standard and custom metadata across NAS, cloud, and object storage, without moving the underlying data. It captures system metadata, content metadata, context metadata, and custom metadata in a single, elastic schema that performs consistently whether the index contains a million files or a hundred billion.
The Komprise Global Metadatabase is a fully managed, distributed metadata catalog that continuously indexes standard and custom metadata across NAS, cloud, and object storage, without moving the underlying data. It captures system metadata, content metadata, context metadata, and custom metadata in a single, elastic schema that performs consistently whether the index contains a million files or a hundred billion.
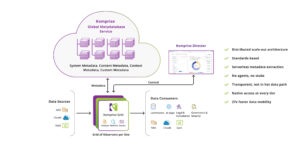
Indexing happens continuously and in place. The Global Metadatabase connects to storage systems using standard protocols, reading file system metadata directly without requiring agents on production storage or disrupting hot data paths. As files are created, modified, or accessed, the index updates automatically, so the catalog reflects the current state of the data estate rather than a stale snapshot.
KAPPA data services extend the index to proprietary formats. Where standard indexing reaches its limit, such as a DICOM header, a genomics BAM file, or a CAD drawing, KAPPA data services apply serverless, format-specific extraction logic to pull out the metadata the file actually contains. That extracted metadata writes back into the Global Metadatabase as a searchable tag, alongside the file’s standard system metadata, making previously opaque content as queryable as any other file. The original source file itself is never modified. Tags, classifications, and enriched attributes live in the Global Metadatabase, not inside the file, which means enrichment carries no risk of corrupting or altering production data.
Komprise Deep Analytics is the query layer built on top of the index. IT, data engineering, and compliance teams use it to search and filter billions of files by any combination of system and custom metadata attributes, with consistent performance regardless of scale. A user builds and saves a query, then selects that same query when creating a Smart Data Workflow or a tiering and archiving plan. The moment a query is put into service that way, Komprise creates a locked copy of it called a system query, so the workflow or plan always runs against the exact criteria that were in effect when it was set up. If the underlying user query is later edited, the running workflow is not silently affected: the system query stays locked until someone deliberately stops the plan, re-selects the updated query, and restarts it. That locking behavior is a safety mechanism, preventing a query edit from unexpectedly changing what gets tiered, archived, or deleted. Komprise Intelligent AI Ingest uses the same pattern to deliver curated datasets to AI pipelines, and Transparent File Tables expose the same index as SQL-queryable tables in Snowflake and Databricks.
This is the architecture shown in the diagram below: a single Global Metadatabase Service sitting above every storage silo, capturing system, content, context, and custom metadata without ever sitting in the hot data path, and making that metadata available as the foundation for every AI, governance, and analytics workflow built on top of it.
The Komprise Global Metadatabase Compared to a Traditional Metadata Catalog
| Capability | Traditional Metadata Catalog | Komprise Global Metadatabase Actionable |
|---|---|---|
| Scope | Typically built for a single storage system or data type, requiring separate catalogs for NAS, object storage, and cloud environments | Indexes across every storage silo, vendor, and location simultaneously in one unified, queryable namespace |
| Data movement required | Often requires copying, scanning, or replicating files into a central system to build the catalog | Indexes metadata in place using standard protocols, without moving or copying the underlying files |
| Proprietary file formats | Limited to file system attributes; cannot read content inside DICOM, BAM, CAD, or other domain-specific formats | KAPPA data services extract content metadata from proprietary formats and write it back as searchable tags |
| What it produces | A static, descriptive record of what data exists, primarily useful for search and discovery | An actionable index that other systems query and act on directly, not just a passive reference |
| Taking action on results | Typically requires exporting results to a separate tool to actually do anything with them, such as moving, tagging, or governing data | A saved query can be selected when creating a Smart Data Workflow or tiering plan; Komprise locks that query as a system query, so the workflow runs against fixed criteria even if the original query is later edited |
| Governance and AI workflows | Governance and AI curation must be built as separate processes layered on top of the catalog | Governance, tiering, and AI curation are native capabilities built directly on the same index, with no separate integration layer |
| Maintenance at scale | Re-scanning or re-indexing the full environment is often required to keep the catalog current | Continuously updated as files are created, modified, or accessed, reflecting the current state of the data estate automatically |
Global Metadatabase Frequently Asked Questions
What is a global metadatabase?
A global metadatabase is a unified, continuously updated index of metadata that spans an organization’s entire unstructured data estate across every storage silo, vendor, and location. It captures information about files, including system attributes, content details, business context, and custom domain-specific tags, in a single queryable namespace, without requiring the underlying files to move or be copied.
How is a global metadatabase different from a traditional metadata catalog?
Traditional metadata catalogs are typically built for a single storage system or data type, which means organizations with data spread across multiple NAS systems, object stores, and cloud providers end up with several disconnected catalogs. A global metadatabase indexes across all storage silos simultaneously, creating one unified, queryable index regardless of where files physically reside. This eliminates the fragmentation that makes cross-silo discovery and governance difficult with traditional, single-system catalogs.
Why is a global metadatabase considered the foundation for enterprise AI?
Every AI initiative depends on knowing what data exists, where it lives, and whether it is safe and relevant to use. A global metadatabase provides that foundational visibility once, continuously, so that AI curation, governance, and analytics workflows can all query the same authoritative source of truth rather than each building their own discovery process against a fragmented data estate. Without this foundation, AI pipelines are built on unknown, ungoverned, and likely duplicate-heavy data, which directly degrades AI accuracy and increases compliance risk.
What types of metadata does a global metadatabase capture?
A complete global metadatabase captures four categories of metadata. System metadata includes file name, size, type, owner, and creation and access dates. Content metadata describes what is inside the file. Context metadata captures how a file relates to other data and business processes. Custom metadata includes domain-specific attributes extracted from proprietary file formats, such as DICOM headers, genomics BAM files, or CAD drawings. Together these four categories turn a scattered file estate into a structured, analyzable, AI-ready asset.
How does Komprise build a global metadatabase without moving data?
The Komprise Global Metadatabase connects to storage systems using standard protocols and indexes metadata directly, without requiring files to be copied, scanned in bulk, or moved to a separate system. KAPPA data services extend that indexing to proprietary file formats by applying serverless, format-specific extraction logic that reads content metadata and writes it back to the Global Metadatabase as a searchable tag. The result is a continuously current index built entirely on metadata operations, with the underlying files remaining exactly where they started.
What can organizations do with a global metadatabase once it exists?
Once a global metadatabase is in place, every downstream workflow can query it as a shared source of truth. Deep Analytics enables search and filtering across billions of files by any metadata attribute. A saved query can then be selected when creating a Smart Data Workflow or a tiering and archiving plan. At that point Komprise locks a system copy of the query, so the workflow always runs against the exact criteria in effect when it was set up, even if someone later edits the original user query. This prevents an accidental query change from silently altering what gets tiered, archived, or governed. Komprise Intelligent AI Ingest uses curated queries the same way to deliver the right data to AI pipelines. Transparent File Tables expose the same index as SQL-queryable tables in platforms like Snowflake and Databricks, giving data engineering teams direct access to unstructured file metadata using the tools they already use.
What is the difference between a user query and a system query in Komprise Deep Analytics?
A user query is any query a person builds and saves in Deep Analytics to search or filter the Global Metadatabase. A system query is created automatically the moment that user query is put into service, meaning it is selected as the basis for a Smart Data Workflow or a tiering and archiving plan. Komprise locks a copy of the query at that point, so the running workflow always executes against the exact criteria that were in effect when it was set up. If someone later edits the original user query, the locked system query is unaffected, which prevents an unintended query change from silently altering what gets tiered, archived, governed, or deleted. To update a running workflow with new criteria, a user must stop the plan, re-select the updated query, and restart it deliberately.
Does tagging or enriching a file with Komprise modify the original source file?
No. Komprise never modifies or changes the original source data. When a file is tagged, classified, or enriched, whether through KAPPA data services, manual tagging, or a sensitive data scan, that information is stored as metadata in the Global Metadatabase, not written into the file itself. This means enrichment carries no risk of corrupting, altering, or otherwise touching production data, and the same underlying file can be enriched, re-classified, or re-tagged repeatedly without ever changing the file on storage.
How does the Global Metadatabase prepare unstructured data for AI and RAG pipelines?
Before any file enters an AI or RAG pipeline, it needs to be discovered, classified, and curated, and that requires knowing what data exists across every storage silo in the first place. The Global Metadatabase provides that foundation: a continuously updated, queryable index of every file’s metadata, including content and custom attributes extracted by KAPPA data services. Deep Analytics queries that index to curate the exact dataset a specific AI use case requires, filtering out duplicate, stale, or irrelevant files before they are chunked, embedded, or indexed in a vector database. Without this upstream curation step, RAG pipelines ingest raw, unclassified file dumps, which is the primary cause of poor retrieval accuracy and hallucination risk in enterprise AI deployments. See ROT data.
What role does metadata play in retrieval-augmented generation (RAG)?
Metadata is what allows a RAG pipeline to retrieve content that is not just topically similar but also current, authorized, and relevant to the business context of a query. Chunks produced from files indexed in the Global Metadatabase can carry jurisdiction, sensitivity classification, file origin, and domain-specific tags alongside their text content. Retrieval systems that support metadata filtering use those attributes to narrow results before evaluating semantic similarity, which is why metadata-enriched retrieval consistently outperforms retrieval based on semantic similarity alone. The Global Metadatabase is the source of that metadata for every file across the enterprise estate, making it the foundation that determines whether a RAG pipeline is trustworthy or merely plausible-sounding.