 A non-disruptive, highly automated, easily customizable approach to preparing clinical data for AI.
A non-disruptive, highly automated, easily customizable approach to preparing clinical data for AI.
Healthcare organizations are sitting on billions of imaging files that hold the keys to more effective treatments and personalized care. Largely, this data is unusable.
Across hospitals and health systems, millions of DICOM files are stored across PACS (Picture Archiving and Communication Systems), VNA (Vendor Neutral Archives), NAS systems and cloud storage.
These files contain extraordinarily rich clinical information ripe for mining. But when it comes to powering clinical AI, that wealth of information is effectively locked away.
The reason behind this is a fundamental mismatch between how DICOM data is stored and what AI pipelines need. Komprise AI Preparation and Process Automation (KAPPA) data services was developed to connect the dots so DICOM files are AI-ready. Read the blog.
The hidden data problem in medical imaging
DICOM (Digital Imaging and Communications in Medicine) has been the standard format for medical imaging for decades. It was designed for storage and transmission, not analytics.
Each DICOM file carries detailed contextual metadata embedded in its file headers. But that metadata is invisible to the storage layer. What the file system sees is a filename, a size, a modification date, and an owner but nothing about the patient, the study type, or the imaging protocol.
This is the core problem:
- The metadata that matters for AI exists, but it is buried inside the file and difficult to access at scale.
- Medical imaging datasets are scattered across PACS and storage systems, making it difficult to locate specific scans.
- There is no efficient way to search, filter, or tag DICOM files based on clinical attributes.
- DICOM images are difficult to use in analytics pipelines and AI workflows without preprocessing.
- Raw imaging files cannot be fed directly into AI training pipelines.
Meanwhile, demand for clinical AI continues to grow. Imaging and radiology are top AI use cases in clinical practice and most (90%) healthcare organizations report at least partial implementation of AI tools for medical imaging, according to research published in the Journal of American Medical Informatics Association (JAMIA).
What clinical AI data preparation requires
Clinical AI depends on access to data with precise clinical context. Without it, the risk of “garbage in, garbage out” is very real.
Preparing imaging data for AI typically involves:
- Extracting DICOM metadata such as modality, patient ID, scan type, and acquisition date;
- Tagging files so they can be cataloged, searched, and governed;
- Converting images to formats like JPG or PNG for visualization where needed;
- Exporting structured metadata into formats such as Apache Iceberg tables for scalable analytics;
- Curating datasets and making them accessible to AI pipelines.
Just as important, this process must happen without disrupting clinical workflows, modifying PACS or VNA systems or creating persistent duplicate copies of data that increase storage costs.
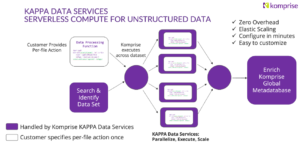
KAPPA Data Service for DICOM Metadata Extraction
Komprise AI Preparation and Process Automation (KAPPA) data services offer a fundamentally different approach.
- KAPPA is a serverless compute framework for unstructured data that allows organizations to run custom functions directly on files in place. With just a few lines of Python code, teams can define how data should be processed, without provisioning infrastructure or building complex pipelines.
- For DICOM workflows, this means a function can open a file, extract the embedded header metadata, and store that information as searchable metadata. This works without requiring proprietary connectors or plug-ins to each PACS or VNA system.
- KAPPA handles the processing and infrastructure at scale, without touching PACS or VNA applications and without relying on brittle plugins that are hard to set up and expensive to maintain. KAPPA operates as a layer above the storage environment, not inside the application stack.
- Importantly, the extracted metadata persists even if the underlying data moves across storage tiers.
Connect KAPPA services together for an AI workflow
Another benefit of KAPPA is that it fits into Komprise Smart Data Workflows which means you can chain KAPPA services into a larger workflow.
For example, say you want to extract DICOM metadata and then use that to search and curate a dataset such as chest pathology images and convert these images to JPEG for faster AI ingest. With KAPPA, you can chain a DICOM extraction KAPPA service with a KAPPA service that converts images to JPEG to accomplish the end-to-end workflow.
What KAPPA means for AI and analytics
The result is that imaging data that was previously opaque becomes AI-ready. AI teams can now search and filter datasets using real clinical criteria. For example, they can identify CT scans from the last two years, MRI studies using a specific protocol, or scans from a particular scanner model. And they can do this without moving a single file or spending months on data engineering.
This serverless Komprise approach enables:
- Faster imaging dataset discovery;
- Improved clinical research productivity;
- Easier dataset curation for AI model training;
- Direct access for AI agents, analytics platforms, and machine learning pipelines.
Why this matters now
As clinical AI becomes more prevalent and begins to show measurable ROI, IT infrastructure teams are under pressure to deliver AI-ready data on demand. That means supporting more requests from clinical and research teams, while maintaining governance, controlling costs, and avoiding disruption to existing systems.
The takeaway
KAPPA data services provides a practical way to meet AI data workflow and preparation requirements by automating DICOM metadata extraction and turning unstructured imaging data into structured, searchable, and governed datasets.
It allows healthcare organizations to prepare data for AI without costly manual processes and without changes to clinical applications. In doing so, it transforms medical imaging data from something that is simply stored into something that can be actively used for AI and analytics.
KAPPA data services are currently in an early access program for customers. Contact your Komprise account team to discuss specific use cases. To schedule a demonstration and learn more visit: Komprise.ai/KAPPA


