Data Management Glossary
Semantic Layer
What is a Semantic Layer?
A semantic layer is a data abstraction layer that translates complex data structures into business-friendly terms, enabling users and applications to access, query, and analyze data consistently without needing to understand underlying schemas or storage systems.
A semantic layer sits between raw data sources and end users or applications. It provides:
- Standardized definitions of metrics and dimensions
- Business-friendly naming conventions
- Consistent logic for calculations and queries
This allows different users, across analytics, business intelligence (BI), and AI, to work from a single, trusted view of data.
Historically, semantic layers have been tightly associated with structured data environments such as data warehouses and BI platforms.
A Brief History of the Semantic Layer
The concept of the semantic layer dates back to the 1990s with early business intelligence platforms like Business Objects, which pioneered a business-friendly abstraction layer over relational databases.
Business Objects, which was acquired by SAP in 2007) introduced:
- A “universe” model that mapped complex schemas into simple business terms
- Patented approaches to semantic abstraction and query generation
This innovation made it possible for non-technical users to run queries and build reports without writing SQL, laying the foundation for modern BI tools.
Over time, the semantic layer evolved with:
- Data warehouses and OLAP systems
- Modern BI platforms (e.g., Looker (Google), Power BI (Microsoft)
- Lakehouse architectures and metrics layers
Why the Semantic Layer Matters Now
The semantic layer has become increasingly important as organizations adopt data fabric architectures and modern AI-driven data strategies.
Key drivers include:
- Data fragmentation: Data is distributed across cloud, on-prem, and multiple storage systems
- Consistency challenges: Different teams define metrics and data differently
- AI adoption: AI systems require clean, well-defined, and context-rich data
- Self-service analytics: More users need access to data without technical expertise
In a data fabric model, the semantic layer plays a critical role by:
- Providing a unified view across distributed data sources
- Enabling consistent interpretation of data across tools and teams
- Supporting both human and machine (AI) data consumption
Limitations of Traditional Semantic Layers
Traditional semantic layers have primarily focused on:
- Structured data (databases, warehouses)
- Semi-structured data (JSON, logs in analytics platforms)
However, they have largely excluded unstructured data, such as:
- Files (documents, PDFs, images)
- Media content
- Email and collaboration data
This creates a major gap because:
- Over 80% of enterprise data is unstructured
- Valuable context for AI and analytics is often locked in files
- Traditional semantic layers lack visibility into file-based data
Who Needs a Semantic Layer?
Semantic layers are designed to serve multiple audiences:
Business analysts and BI users
- Access data using familiar business terms
- Build reports and dashboards without SQL
Data analysts and data engineers
- Ensure consistent definitions across datasets
- Reduce duplication of logic and transformations
Data scientists and AI/ML teams
- Access curated, well-defined datasets
- Improve model accuracy with consistent inputs
Business stakeholders and decision-makers
- Consume trusted data insights
- Avoid conflicting metrics across teams
The Semantic Layer Missing Piece: Unstructured Data
As organizations move toward AI-driven insights, unstructured data has become critical, but remains poorly integrated into semantic layers.
Challenges include:
- Lack of standardized metadata
- Difficulty in indexing and searching file-based data
- Limited visibility into data usage and value
Without incorporating unstructured data, semantic layers provide an incomplete view of enterprise data.
How Komprise Extends the Semantic Layer to Unstructured Data
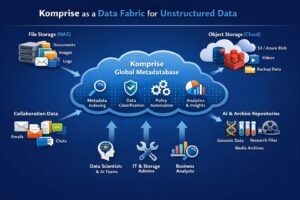 Komprise enhances and complements the semantic layer with its Global Metadatabase, which provides a unified metadata index across all unstructured data environments.
Komprise enhances and complements the semantic layer with its Global Metadatabase, which provides a unified metadata index across all unstructured data environments.
With Komprise, organizations can:
- Discover and index unstructured data globally: Across NAS, object storage, and cloud environments
- Apply metadata-driven intelligence: Including access patterns, ownership, size, and age
- Classify and categorize data at scale: Identifying sensitive, redundant, or high-value data
- Curate datasets for AI and analytics: Filtering out noise and surfacing relevant data
Why this matters
Komprise effectively enables a semantic layer for unstructured data, allowing organizations to:
- Extend data fabric architectures beyond structured systems
- Provide context and meaning to file-based data
- Improve AI outcomes with better data selection and preparation
What is the difference between a semantic layer and a data catalog?
A semantic layer defines how data is interpreted and queried, while a data catalog focuses on discovering and inventorying data assets.
Why has the semantic layer become more important with AI?
AI systems depend on consistent, well-defined data. A semantic layer ensures that data is interpreted correctly across models and applications.
Can traditional semantic layers work with unstructured data?
Most are limited to structured and semi-structured data, leaving a gap in managing file-based data.
How does Komprise complement the semantic layer?
Komprise extends semantic capabilities to unstructured data through its Global Metadatabase, enabling discovery, classification, and curation at scale.
Key Takeaway
A semantic layer makes data understandable and usable, but traditionally only for structured data.
Komprise extends this concept to unstructured data, enabling organizations to build a complete, AI-ready data fabric that includes all enterprise data.