Data Management Glossary
Data Fabric
What is a Data Fabric?
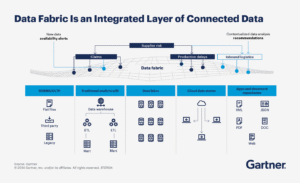
A data fabric is an architectural approach that provides a unified, consistent way to access, manage, integrate, and govern data across distributed environments, including on-premises, cloud, and hybrid systems, using metadata and automation.
A data fabric creates a virtualized data layer that connects disparate data sources, databases, data lakes, cloud storage, applications, and files, so they can be accessed and used as if they were part of a single system.
While the definitions vary by vendor and industry analysts (see Gartner data fabric) core data fabric capabilities include:
- Unified data access across environments
- Metadata-driven data discovery and integration
- Centralized governance and policy enforcement
- Automation of data management tasks using AI/ML
Unlike traditional architectures that require moving data into a central repository, a data fabric enables data to remain in place while still being accessible and usable across the organization.
A Brief History of Data Fabric
The concept of data fabric emerged in the late 2010s as organizations struggled with:
- Explosive data growth
- Hybrid and multi-cloud environments
- Increasing data silos across systems
Analysts such as Gartner popularized the term as a metadata-driven approach to data integration and management, emphasizing the use of “active metadata” to automate data pipelines and reduce manual effort.
Earlier foundations of data fabric include:
- Data integration tools (ETL/ELT platforms)
- Data virtualization layers
- Data catalogs and metadata management systems
Data fabric builds on these by combining them into a unified, composable architecture.
Why Data Fabric Matters Now
Data fabric has become critical due to several converging trends:
- Data is everywhere: distributed across clouds, data centers, and edge
- AI requires better data: clean, contextual, and accessible datasets
- Data silos persist: limiting analytics and business agility
- Skills gaps: fewer experts to manage complex pipelines
Data fabric addresses these challenges by:
- Reducing complexity in data integration
- Accelerating access to data for analytics and AI
- Leveraging metadata to automate data management
In modern enterprises, data fabric is often positioned as the foundation for AI-ready data infrastructure.
Data Fabric vs. Data Mesh
Data fabric and data mesh are often confused but serve different purposes.
Data Fabric:
- Technology-driven approach
- Focuses on integration, automation, and metadata
- Provides a unified data access layer
Data Mesh:
- Organizational and architectural approach
- Focuses on decentralized data ownership
- Treats data as a product owned by business domains
Key distinction:
- Data fabric = how data is connected and managed
- Data mesh = how data ownership and governance are structured
They are complementary:
- Data mesh defines who owns the data
- Data fabric enables how that data is accessed and integrated
How Data Fabric Fits with Lakehouse Architecture
A data fabric does not replace data lakes or data lakehouses – it connects and enhances them.
Data Lakehouse Architecture:
- Combines data lakes (low-cost storage) with data warehouses (structured analytics)
- Uses formats like Iceberg and Delta
Data Fabric Role:
- Connects lakehouse data with other sources
- Provides unified access across environments
- Automates data integration and governance
Lakehouse = where data is stored and analyzed
Data fabric = how data is connected, discovered, and governed across systems
Vendor Landscape: Who is Driving Data Fabric?
Data fabric is a broad architectural category with multiple vendors contributing different components. No single vendor delivers a complete data fabric. It is a composable architecture built from multiple components.
Platform and data integration vendors:
- IBM
- Informatica (now Salesforce)
- Oracle
- SAP
These vendors focus on:
- Data integration
- Data governance
- Data catalogs and pipelines
Storage and infrastructure vendors:
- NetApp
- Dell Technologies
- Hewlett Packard Enterprise
These vendors extend data fabric into:
- Storage systems
- Hybrid cloud infrastructure
- Data services across environments
For example:
- NetApp promotes a data fabric to unify data across on-prem and cloud environments
- Hewlett Packard Enterprise delivers a unified data platform for AI and analytics across hybrid environments
The Data Fabric Missing Piece: Unstructured Data
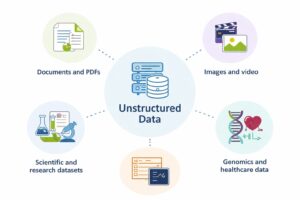
Most data fabric implementations focus on:
- Structured data (databases, warehouses)
- Semi-structured data (logs, JSON, event streams)
But they often lack deep visibility into unstructured data (files, documents, media)
This is a critical gap because:
- Over 80% of enterprise data is unstructured
- Valuable AI training data resides in files
- Metadata for unstructured data is often incomplete or inaccessible
Without unstructured data, a data fabric provides an incomplete view of enterprise data.
How Komprise Extends Data Fabric with the Global Metadatabase
A data fabric connects and manages data across the enterprise, but most implementations overlook unstructured data. Komprise plays a critical role in enabling a complete data fabric, especially for unstructured data.
Komprise provides the metadata intelligence needed to bring unstructured data into the data fabric, enabling a truly AI-ready, enterprise-wide data foundation.
Key capability: Global Metadatabase
Komprise builds a global metadata index across all file and object storage, enabling:
- Unified visibility across NAS, object storage, and cloud
- Analytics-driven insights into data usage, age, ownership, and value
- Data classification and tagging at scale
- Policy-based data movement and optimization
What is the Komprise Role in a Data Fabric Architecture?
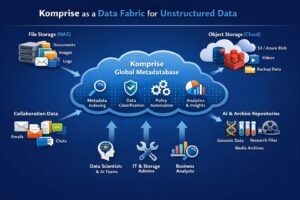
Komprise acts as the unstructured data intelligence layer, enabling:
- Integration of file-based data into the data fabric
- Metadata-driven automation for data placement and lifecycle
- Curation of high-value datasets for AI and analytics
Data fabric depends on metadata as its foundation. Komprise extends that foundation by:
- Turning unstructured data into active, usable metadata
- Enabling organizations to include all enterprise data, not just structured data, in their data fabric
In effect, Komprise helps organizations build a complete data fabric that includes unstructured data.
Learn more about Komprise Intelligent Data Management.
The Role of a Semantic Layer in a Data Fabric
A semantic layer plays a critical role within a data fabric by providing consistent meaning, context, and business definitions across distributed data sources.
While a data fabric connects and manages data across environments, the semantic layer ensures that:
- Data is interpreted consistently across users and applications
- Business metrics and definitions are standardized
- Queries return trusted, governed results regardless of where data resides
In a modern architecture:
- The data fabric provides access and integration
- The semantic layer provides meaning and consistency
Together, they enable both human users and AI systems to understand and use data correctly at scale.
Data Fabric vs. Semantic Layer: What’s the Difference?
Although they are complementary, data fabric and semantic layer serve different purposes:
Data Fabric
- Focus: Data connectivity and management
- Scope: Infrastructure and architecture
- Goal: Make data accessible and manageable anywhere
- Capabilities:
- Data integration across environments
- Metadata-driven automation
- Governance and policy enforcement
Semantic Layer
- Focus: Data interpretation and usability
- Scope: Logical/business abstraction layer
- Goal: Make data understandable and consistent
- Capabilities:
- Business-friendly definitions
- Metric standardization
- Query abstraction
Key distinction:
- Data fabric answers: “Where is the data and how do I access it?”
- Semantic layer answers: “What does the data mean and how should I use it?”
How Komprise Extends the Semantic Layer Within a Data Fabric
Komprise bridges this gap by extending semantic capabilities to unstructured data through its Global Metadatabase.
Komprise provides:
- A global metadata index across all file and object storage
- Analytics on data usage, access patterns, and ownership
- Built-in data classification and data tagging
This allows organizations to:
- Apply meaning and context to unstructured data
- Identify high-value datasets for analytics and AI
- Integrate file-based data into broader data fabric architectures
Why this matters
Modern AI and analytics require:
- Not just access to data
- But context, quality, and relevance
By enriching unstructured data with metadata and analytics, Komprise enables organizations to:
- Incorporate unstructured data into semantic models
- Improve AI data pipelines and outcomes
- Build a complete, end-to-end data fabric
A data fabric connects data, and a semantic layer defines its meaning, but both have historically overlooked unstructured data. Komprise fills this gap by providing the metadata foundation needed to bring unstructured data into both the data fabric and the semantic layer, enabling a truly AI-ready data architecture.
Learn more about the Komprise Data Experience.
What problem does a data fabric solve?
It eliminates data silos by providing unified access, integration, and governance across distributed data environments.
Is data fabric a product or an architecture?
It is an architectural approach composed of multiple technologies and tools.
How is data fabric different from a data lake?
A data lake stores data, while a data fabric connects and manages data across multiple systems.
Why is metadata important in a data fabric?
Metadata enables discovery, integration, automation, and governance across distributed data sources.
How does Komprise support data fabric?
Komprise extends data fabric capabilities to unstructured data through its Global Metadatabase, enabling visibility, classification, and optimization at scale.