The landscape of data storage, unstructured data management and cloud are constantly in flux. Komprise sits right in the middle of all this change. Read on for some definitions of a few top terms in the space and check out the Data Management Glossary for more definitions.
What is Unstructured Data Management?
Unstructured Data Management is a category of software that has emerged to address the explosive growth of unstructured data in the enterprise and the modern reality of hybrid cloud storage. As further explained in ITProToday: “Unstructured data is more difficult to manage than unstructured data as it doesn’t have a uniform format, even if the data source is the same. Indeed, managing it in the way structured data is managed is something of a novel idea, as it’s only been feasible to mine it for information since big data analytics and AI have taken off.”
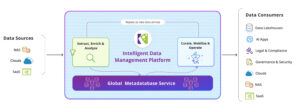
Komprise Intelligent Data Management delivers a unique approach to this market segment, with a comprehensive platform that includes: data insight through analytics, data mobility, open standards, cloud native access and a non-disruptive user experience with Transparent Move Technology. Komprise works across file and object storage to analyze and manage unstructured data at scale. Komprise Intelligent Data Management enriches unstructured metadata, unifies visibility, tiers to cut 70%+ costs, migrates petabytes and automates AI workflows.
Data Storage Terms
What is NFS versus SMB?
NFS and SMB are network file-sharing protocols, as defined here in our data management glossary:
Network File System (NFS): The NFS protocol is one of several distributed file system standards for network-attached storage (NAS). It was originally developed in the 1980s by Sun Microsystems and is now managed by the Internet Engineering Task Force (IETF).
Server Message Block (SMB): SMB is a network communication protocol for providing shared access to files, printers, and serial ports between nodes on a network. SMB is also known as Common Internet File Systems (CIFS).
Microsoft partner Cloud Infrastructure Services delivers these comparisons: “NFS is unbeatable when it comes to medium sized or small files. For larger files, the performance of both protocols is similar. NFS is more appropriate for Linux users, while SMB is more appropriate for Windows users.”
What is NAS?
Network Attached Storage (NAS) is a storage device connected to a network that allows storage and retrieval of data from a centralized location for authorized network users and heterogeneous clients. These devices generally consist of an engine that implements the file services (NAS device) and one or more devices on which data is stored (NAS drives). The purpose of a NAS system is to provide a local area network (LAN) with file-based, shared storage in the form of an appliance optimized for quick data storage and retrieval. NAS is a relatively expensive storage option, so it should only be used for hot data that is frequently-accessed.
What is NAND flash memory?
NAND flash memory is a type of non-volatile semiconductor memory used to store data in solid-state storage devices. Unlike volatile memory such as DRAM, NAND flash memory retains data even when power is turned off. The term NAND comes from the NAND logic gate (“Not AND”) used in the design of the memory cells. This architecture allows NAND flash to store data efficiently in dense arrays, making it ideal for high-capacity storage devices.
What is Storage Reclamation?
Storage reclamation is the process of identifying, relocating, archiving, or removing inactive, redundant, or unnecessary data to recover usable storage capacity and reduce both infrastructure and operational costs. In enterprise environments filled with unstructured data (files, images, backups, research outputs), storage reclamation goes beyond simple cleanup. It is an essential part of storage refresh strategy and a strategic way to right-size storage estates, reduce risk, and optimize long-term data value.
What is Cloud Tiering?

Cloud tiering extends your current storage infrastructure to include cloud data storage resources. Cloud Tiering lets storage administrators set policies to move infrequently accessed data to lower cost storage. The result is better use of expensive primary storage with capacity only used by “hot data” requiring faster access. Cloud tiering can also save significantly on storage spending and protect cold data for disaster recovery, auditing and research needs. Learn about Komprise Transparent Tiering and TMT.
What is Departmental Showback?
Department showback is a financial management practice that involves tracking and reporting on the costs associated with specific departments or business units within an organization. Also see Showback. It is a way to allocate and show the IT or operational costs incurred by various departments or units to help them understand their resource consumption and budget utilization. Department showback is often used as a transparency and accountability tool to foster cost-awareness and responsible resource usage.
AI Terms
What is AI Data Ingestion?
AI Data Ingestion is the process of discovering, preparing and moving data from various sources such as applications and storage systems into AI tools and services for processing, analysis and/or training machine learning (ML) models. AI data ingestion in corporate environments consists primarily of leveraging unstructured data, such as user documents, PDFs, chat and text files, multimedia files, or instrument data.
Since unstructured data is highly distributed across storage silos in enterprises, storage IT professionals need automated systems to search across petabytes of corporate data stores, check for sensitive data, tag data so that it can be discovered more easily and move data to AI with audit reporting. Learn more about Komprise Intelligent AI Ingestion.
What is AI Data Management?
- Finding and curating the right data
- Moving and preparing data for AI pipelines
- Ensuring data is high-quality, compliant, and properly tagged (see data tagging)
- Optimizing where data is stored and how it’s accessed (see data storage cost optimization)
- Tracking data lineage and governance for responsible AI
What is AI Data Extraction?
AI Data Extraction is the automated process of identifying, retrieving, and structuring relevant information from raw data sources, especially unstructured data or semi-structured data content like documents, emails, images, and logs, to make it usable for AI models. This is a critical first step in AI data pipelines because AI systems require well-organized, context-rich inputs to deliver accurate and meaningful results.
Organizations are generating massive amounts of unstructured data, while AI initiatives require trusted, relevant information. AI data extraction helps turn raw enterprise content into usable data faster, reducing manual effort and accelerating time to insight. Learn about Komprise AI Preparation & Process Automation (KAPPA) for automated, custom metadata extraction.
What is AI Compute?
AI compute refers to the computational resources required to run artificial intelligence workloads, including training machine learning models, processing data, and performing inference. These resources typically include GPUs, CPUs, specialized accelerators (e.g., TPUs), and cloud or on-prem infrastructure.
AI compute powers every stage of the AI lifecycle:
- Training: Processing massive datasets to build models
- Inference: Running models on new data to generate predictions
- Data processing: Preparing, filtering, and transforming data before use
AI compute environments can include cloud platforms (AWS, Azure, GCP), on-prem GPU clusters and edge computing systems.
What are RAG Pipelines?
RAG pipelines (Retrieval-Augmented Generation pipelines) are AI workflows that combine large language models (LLMs) with real-time data retrieval from enterprise content sources such as file storage, object storage, cloud repositories, databases, and knowledge systems. Instead of relying only on pre-trained model knowledge, a RAG pipeline retrieves relevant information at query time and uses it to generate more accurate, contextual responses.
What is MCP?
The Model Context Protocol (MCP) is an emerging open standard that enables AI models and agents to securely connect with external tools, data sources, and systems in a consistent way. Instead of building one-off integrations, MCP provides a framework for interoperability, allowing agentic AI systems to dynamically pull in context, take actions, and access enterprise resources. MCP makes agentic AI data workflows safe by providing a standardized way to extend AI capabilities, enforce security controls, and ensure reliable connections across different ecosystems.
What is Metadata Governance for AI?
Metadata Governance for AI is the process of managing the descriptive information about enterprise data so artificial intelligence systems can safely, accurately, and efficiently access trusted content. Metadata includes information such as file owner, department, permissions, sensitivity labels, creation date, retention status, storage location, business category, and usage history. Without strong metadata governance, AI tools may retrieve outdated files, expose confidential content, or generate responses from unapproved sources.
Data Terms
What is Metadata?
Metadata is data that describes other data, such as author, date created, date modified and file size. Metadata can be created manually or through automation and is useful in managing unstructured data since it provides a common framework to identify and classify a variety of data including videos, audios, genomics data, seismic data, user data, documents and logs. TechTarget describes several different types of metadata in this article.
What is Metadata Management?
Metadata management is the process of collecting, organizing, storing, and maintaining metadata associated with an organization’s data assets. Metadata means data about data. It provides context, structure, and information about various aspects of data, making it easier to understand, manage, protect and use. Effective metadata management is essential for ensuring data quality, data accuracy, data security and the right data accessibility across an organization’s enterprise data landscape.
What is Metadata Indexing?
Metadata indexing is a valuable capability that gives IT managers full visibility of unstructured data across hybrid storage, from on-premises to the cloud. Storage systems automatically create basic metadata for the unstructured data they store, such as author/owner timestamps, file size and type, and time of last access. Metadata indexing gives visibility so IT managers and storage administrators can optimize storage. They can identify cold data that can be tiered or archived to cheaper storage and to see the rate of data growth, among other core metrics.
What is Data Tagging?
Data tagging is the process of adding metadata to your file data in the form of key value pairs. These values give context to your data, so that others can easily find it in search and execute actions on it, such as move to confinement or a cloud-based data lake. Data tagging is valuable for research queries and analytics projects or to comply with regulations and policies. To learn more about data tagging with Komprise, read this blog.

What is Data Classification?
Data classification is the process of organizing data into tiers of information for data organizational purposes. It is essential to make data easy to find and retrieve so that your organization can optimize risk management, compliance, and legal requirements. Data classification helps organizations manage data for compliance, security, and AI workflows. It is especially important for identifying sensitive data such as PII. Written guidelines are essential in order to define the categories and criteria to classify your organization’s data. It is also important to define the roles and responsibilities of employees in the data organization structure.
What are Unstructured Data Workflows?
Unstructured data workflows can include a variety of processes and technologies, such as data management tools, document management systems, content management systems, and collaboration platforms. Data is no longer static and needs to move between systems and clouds to satisfy changing requirements and to support big data and AI/ML initiatives. Technologies and processes that automate and streamline these workflows can shave significant time and costs from finding, preparing and moving data into data lakes and AI tools or to meet compliance requirements. Read about Komprise Smart Data Workflows.
——————-


