

CTO and co-founder, Komprise
A successful software company depends upon the care that goes into developing the right technical foundation for near-term and long-term use cases. I had a chat with Mike Peercy, CTO and co-founder of Komprise, about the core elements of the Komprise architecture for unstructured data management and mobility and why it matters for our customers.
_______________________
How would you describe the core components of the Komprise data management architecture?
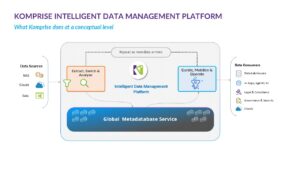
Mike: First, we have a scalable architecture. This is critical so that our customers can scale out each site with shares and data as needed and scale among sites to bring data from many places into the same view. The Komprise Global Metadatabase is the second core piece of the architecture. It stores the metadata for Deep Analytics and Deep Analytics Actions. Finally, we have our patented Transparent Move Technology™ (TMT), which drives the ability to save storage costs without user disruption and without lock-in. On average, our customers are saving 70% on storage and backup costs by using Komprise to help identify data which can move to less expensive archival storage.
_______________________
What makes the Komprise architecture scalable in particular?
Mike: Our distributed, scale-out architecture means a few things. Firstly, it is stateless, which means that the grid of Komprise Observers and proxies (these are our data movers) do not share anything between them. This enhances the performance of the software as data volumes grow, along with reducing complexity and errors. Since Komprise runs as a service, there’s no central database for the customer to install or manage. All of this means that customers can scale deployment at any site to handle more shares and data, whenever they wish, by simply adding more Observers.
_______________________
That seems to advantageous in these times when unstructured data is growing exponentially. Can you tell us a bit more about the Global Metadatabase?
Mike: The Global Metadatabase is the basis for automated data management. Komprise Observers—whether they’re in your data center, at the edge or in the cloud—analyze data quickly and bring it to the Global Metadatabase. This service, built for massive scale, continually indexes all files in place and analyzes all the metadata. Data and storage professionals can search, tag and create curated data sets across storage silos and then copy and move those curated data sets to AI or new storage.
_____________________
Awesome. Now can you give us more detail on TMT as well?
Mike: Yes. TMT is fundamental because it makes things easy for users and eliminates conflicts between data owners and storage administrators. This technology transparently moves files from the source to the target and leaves a dynamic link behind. Users never need to hunt a file down after Komprise moves it. Storage managers never have to ask users again before tiering data, because there’s no change required for users or applications to access their files. The files are also now sitting at the target, typically object storage like AWS S3 or Azure Blob. Moved files are also in native form, which means that users can leverage them there for analysis or other purposes. Finally, TMT eliminates rehydration fees common with storage vendor-based tiering.
_______________________
What have been the greatest technical challenges of building this architecture?
Mike: A global indexing cloud service is very hard to build because it needs to index across files and objects and across silos including datacenters, clouds and vendors. It must have massive scaling capabilities so that it can index across billions of files and thousands of buckets and file shares. Finally, the Metadatabase needs to be a scalable cloud service, analogous to a Google search on file metadata.
Mobilizing unstructured data is also hard to get right. You need to preserve duality of file and object data across silos, enable native cloud services on the data so you can use it in the cloud, and ensure that hot data at the original source is handled by that storage vendor. Finally, we wanted to build a solution which didn’t require the use of proprietary agents or stubs to access files once moved.
Interestingly, in developing TMT end-to-end, we solved the hardest mobility problem first. TMT delivered a foundation to build other mobility functionality, such as file migration or share replication, and provides a great advantage in developing new features.
Read more about Komprise unstructured data management architecture in this white paper.
_______________________
What’s exciting to you about the roadmap for Komprise?
Mike: The data-driven organization today revolves around the liberation of data for broad use by different departments. In a secure way, Komprise aims to empower data end users with self-service and the storage IT and LOB IT teams that support them. Users can tag their own files and create policies to move their data to approved targets, run analysis on it and then further enrich it by adding additional tags. This process brings hidden or forgotten data into the light for new uses, while also giving individuals the power to delete datasets when they are no longer needed or when compliance requirements dictate actions.

_______________________


