Tag and Enrich Data with Custom Workflows at the Edge, Data Center and Cloud
In the previous post we discussed how data mobility is now the key challenge for deriving value from unstructured data via data analytics and AI/ML processes. A significant amount of time in the data analytics workflow is consumed finding and moving data rather than the analytics or AI/ML processing of that data.
Here we discuss how to bring data analytics services to your unstructured data to enrich and refine data sets.
- One useful data analytics service is tagging, where data can be tagged with custom, user-defined tags to enable easier future searches.
- Tagging can also be used to combine related data that are logically or temporally separated into one result set using a common tag or tags.
- You can use tags stored in applications and make them available no matter where your data moves.
You Can Execute Data Tagging Operations Either at the Source of the Data or in the Cloud
Data tagging using Komprise is flexible and customizable. Using APIs, you have the freedom to apply tags to data wherever it’s most convenient for you. So why tag data locally, at the edge?
- Network restrictions — Limited bandwidth, long latency, and costs may make sending massive data sets over the internet problematic. In such cases, searching and narrowing just the right data that needs to be sent to the cloud can speed up data analytics.
- Security — Some customers may not be able to send data over public networks, so processing should be performed at the point of generation.
- Speed — Depending on your workload, it may be faster to bring compute to your data versus your data to compute
- Application-specific metadata — Custom or industry-specific applications, such as a Lab Information Management Systems (LIMS), will have their own set of metadata for files: for example, a device ID in microscopy image files. This metadata will only be available by querying the applications at the local data center.
Regardless of the reason, tagging data at the edge or data center has many benefits and is the first step in enriching your data set before sending it to the cloud for further analysis.
Clinical Research Unstructured Data Tagging Example
As a case in point, we will use the compute power of the Komprise Observers. These key components of the Komprise architecture are virtual appliances that run in VMs deployed adjacent to your data and which analyze and transfer data by custom-defined policies.
When you point Komprise at your different file and object repositories, Komprise automatically indexes all the standard metadata and creates a Global Metadatabase. Users can enrich data with custom tags, which Komprise maintains as your data moves according to your policies.
No matter where your data goes, your tags persist and you can search for them across clouds with Komprise.
To illustrate how you can run any custom function and create custom data workflows using Komprise, we will use a simplistic example of taking a set of files from a Komprise query, running a standard Linux-based search tool to find files that contain a specific term and tagging them systematically through a workflow.
- Our environment has a data set that includes files in Abstract Syntax Notation format (*.asn) , which is an International Standards Organization (ISO) data representation format for data interoperability, commonly used in life sciences.
- We will query the Komprise Global Metadatabase to first find files with extension ASN in directories with “coronavirus” in their name;
- Next we’ll use a standard text search tool run a full text search of these files for “Netherlands.” The files returned by the query will be tagged with “Country=Netherlands” via the Komprise API.

Here are the file and object data tagging steps:
Step 1: Deep Analytics query
First, we use the Komprise Deep Analytics interface to query the Global Metadatabase and find the ASN data that we will refine. For this demo, the data set is small, just 8.9 GB and about 1400 files across a few file shares; in a production environment the data set could easily be petabytes and billions of files stored across many data centers and clouds, across any file storage.
_______________________
Step 2: Select your file
We save a query to select “file type: asn & directory = “coronavirus” and name the query “ASN files under coronavirus”. This refines our data set to just 46 files. We could have Komprise move or copy the results of this query to the cloud if we wanted to further analyze this. But, we actually want to refine the data further as we are only interested in Coronavirus ASN files that have studies done in the Netherlands.

_______________________
Step 3: Create a Komprise tag
Now we create a new query named “Researched in Netherlands” that looks for a tag with name “country” and with the value “Netherlands”.

When we run the query at this point, it returns 0 results; the ASN files have not yet been processed and tagged with a location value.
_______________________
Step 4: Create a Komprise Plan
Next, we create a Komprise Plan that will invoke the text search function to inspect and tag the selected files. To be efficient we only want to process the files identified in our previous query “ASN files under coronavirus” so we use that specific query for our source.

This will enable us to run our search function against this specific data set. The Observers will now extract these select files to search for the term “Netherlands” and apply the tag “country: Netherlands”.
_______________________
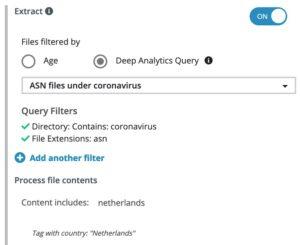
This plan will run on a scheduled basis to continually find new data that meets the criteria we specified.
_______________________
Step 5: Review your result set
Returning to the Deep Analytics function within Komprise, we can now re-run our query looking for files tagged with “country: Netherlands”

Now we see five files that meet our criteria. The researcher can take action on this specific data set in a clinical study, for example, and copy this precise data set to the cloud to run AI/ML processes. This same set of tags could be used for other purposes, such as to enforce GDPR data locality rules or data retention policies.
The combination of Komprise Intelligent Data Management with APIs and the customer’s applications provide an open framework to drive innovation and derive greater value.
How Does This Work?
We used a text search application that extracts data and stores it in an open format (JSON). We then used the Komprise API to apply this data to each file as a tag and make it available in the Komprise Global Metadatabase. Komprise uses the industry standard Swagger UI interface to guide customers use of the API.
How Do You Create Systematic Data Workflows Across Repositories?
While this was a specific scenario, Komprise provides an Intelligent Data Management and Mobility framework via an API that can interact with advanced data analytics applications, across industries and disciplines, such as life sciences and manufacturing.
The ability to use Komprise to search, find, apply tags and then take action makes it possible for customers to get faster value from enriched data sets. You can use this to build your data pipelines with any custom workflows. Once you design your queries and set the policies in Komprise, it automatically and continuously executes your data pipeline.
In this example, as new ASN files are created, Komprise will automatically find them, tag the ones with Netherlands and update the query results. You can also have Komprise move these results or copy them to the cloud for further data analytics.
In our next blog we team up with AWS to discuss processing and tagging data with AWS cloud data services.
Read the blog post: Using Amazon Macie with Komprise for Detecting Sensitive Content in On-Premises Data
_______________________


