This article was adapted from its original version on CDO Trends.
Serverless started in the world of compute, but the idea behind it is bigger than functions and containers. At its heart, serverless is about taking infrastructure headaches off your plate so teams can focus on requirements and results instead of plumbing.
That same mindset is now making its way into unstructured data management, shifting IT responsibilities from managing infrastructure to getting value from data.
Just as serverless functions such as AWS Lambda automate the provisioning of physical servers, serverless for unstructured data automates steps to provision data processor infrastructure and run functions across large, petabyte-size datasets.
Why serverless data management and why now?
Unstructured data, piling up for decades and often viewed as a digital landfill, is suddenly in high demand for AI. But this poses a problem because unstructured data lacks unifying schema, is of poor quality, and much of it is irrelevant for any given use case. Finding the needle in the haystack for a project is not for the weak of heart.
Writing data processing applications to accomplish this is not trivial:
- It requires visibility into scattered storage silos and repositories, scaling to scan and process huge volumes of content, and orchestration to coordinate jobs across different environments.
- Also, workloads spike unpredictably, so you need elasticity and ways to spin resources up and down without wasting money.
- Data processing needs to be customized to each industry, enterprise and its unique security requirements.
- Unstructured file and object data must be sorted, cleaned up, governed and leveraged properly for AI success. This begins with analysis across storage, data classification and metadata enrichment.
Serverless data management brings a lightweight architecture that enables rapid customization of data processing functions to meet each enterprise’s unique needs.
AI data management requires complex dataops
AI data management, a top need identified in the Komprise 2026 State of Unstructured Data Management, is continually evolving. Precise, rapid unstructured data curation is needed. Blindly copying petabytes of data into an AI tool or service is expensive, wasteful, time-consuming and won’t result in accurate outcomes.
An emerging tactic is enriching standard system metadata to meet niche industry and security requirements for AI data pipelines.
- Metadata enrichment adds contextual, descriptive, or business-relevant information to your existing unstructured data, making it useful for AI.
- Rich, easily discoverable metadata allows employees to rapidly curate what they need for AI projects while excluding duplicate, non-authoritative, and sensitive or regulated data.
- Custom metadata operations require manual work, such as: applying enterprise-specific ERP project tags to R&D files or reading custom headers from medical images using the hospital’s semantic context.
Serverless versus ETL for data management
IT organizations have relied on Extract, Transform and Load (ETL) tools to perform the data processing functions for structured data. ETL approaches work well for structured data, but are too costly, complex and inflexible for the dynamic nature of unstructured data.
Komprise incorporates serverless compute to bring a global view of data across silos, with Komprise AI Preparation & Process Automation (KAPPA). With large-scale analysis and centralized metadata, this provides visibility that would be costly and complex to assemble on your own.
From there, Komprise handles the heavy lifting. It can spin up parallel compute resources, bring cloud infrastructure online when needed, and run processing functions across petabytes of data and billions of files. The operator’s mindset shifts from “How do I run this?” to “What outcome do I want?”
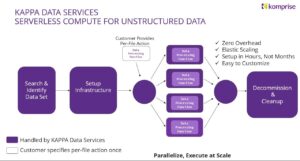
New requirements for agile, low-code, agentic AI processes
Serverless data management reduces the need for custom tooling and deep infrastructure tinkering. Teams focus on governance, planning, and business alignment while the platform handles execution.
Speed matters too. Traditional data projects require months of planning and setup before meaningful work even starts. By then, priorities may have changed. A serverless approach shortens that cycle.
Then there’s the reality of hybrid and multi-cloud infrastructure. Data stretches across data centers, edge locations, and multiple clouds, each with its own architecture and performance profiles. A serverless layer that smooths over those differences lets IT leaders manage data more consistently and cost effectively.
A strategic shift, not just a technical one
When infrastructure complexity fades into the background, IT leaders can focus on value-added questions, such as: which data delivers business value, what should be kept or retired, how data can fuel analytics and AI, and how management practices tie into risk and compliance goals.
As unstructured data keeps exploding and AI raises the stakes for well-managed datasets, the winners will be the organizations that treat unstructured data management as a scalable discipline rather than a series of ad hoc efforts.
Learn more about Komprise AI Preparation & Process Automation (KAPPA).
Check out the latest Komprise Best Practices videos and webinars.


