Organizations across healthcare, life sciences, media and entertainment are managing vast libraries of image files that hold critical operational, legal and compliance value embedded directly inside each file.
- JPEG, TIFF, RAW, and other image formats store visual data captured by cameras, scanners, and imaging instruments.
- EXIF (Exchangeable Image File Format) metadata is a standard embedded in image files at the point of capture. EXIF records camera make and model, date and time of capture, GPS coordinates, image resolution, software used for editing, copyright and artist attribution, and instrument serial numbers.
Image files accumulate at scale across NAS systems, object storage, cloud environments, and departmental shares. The EXIF metadata they carry is rich with operational and compliance value, but largely inaccessible to IT, compliance, and data teams without opening each file individually.
This blog describes how Komprise has a serverless compute function to extract EXIF metadata. A similar process is also applicable to other file formats where metadata is embedded in headers or file contents.
Requirements for AI image data preparation
AI, editorial, and compliance use cases all depend on access to clean, accurately attributed image data with precise contextual metadata. Preparing image data for AI and compliance typically involves:
- Extracting EXIF metadata fields such as camera make, camera model, camera serial number, date and time of capture, GPS coordinates, and software version;
- Tagging files so they can be cataloged, searched, and governed across departments and storage tiers;
- Identifying edited, backdated, or off-instrument images that represent compliance or legal risk;
- Curating datasets by ownership, vintage, location, or device for editorial, clinical, or research use;
- Exporting structured metadata into searchable indexes or analytics platforms for AI pipelines, compliance audits, and rights management tools.
This process must happen without disrupting existing workflows, without requiring changes to upstream applications, and without creating persistent duplicate copies of data that inflate storage costs. This is a significant concern given that image libraries in large organizations can span millions of files across petabytes of storage.
KAPPA Data Service for Image Files
Komprise AI Preparation and Process Automation (KAPPA) data services extract EXIF metadata from image files at scale, enrich the search index, and trigger automated workflows.
KAPPA is a serverless compute framework for unstructured data that allows organizations to run custom functions directly on files in place. With just a few lines of Python code, teams can define how image metadata should be extracted and acted upon without provisioning infrastructure or building complex pipelines.
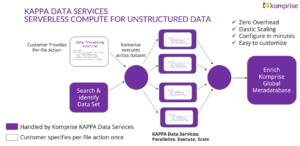
Top use cases for KAPPA with image files:
1. Healthcare: Clinical image compliance and HIPAA governance
A HIPAA or Compliance Officer can use KAPPA to extract EXIF fields including software, date/time, and camera serial from clinical images stored outside the EHR. By surfacing this metadata into the Komprise search index, compliance teams can identify and curate orphaned or edited clinical photos at scale, trigger PII detection workflows on flagged files, and automatically move them to a compliant storage location or quarantine them for review. This process can run automatically and continuously without requiring changes to clinical workflows or imaging systems. This is complementary to the DICOM metadata extraction that Komprise also performs via another KAPPA data service.
2. Media and Entertainment: Editorial image governance and rights management
KAPPA can extract EXIF fields including artist, copyright, and date/time to make a publishing image library searchable by ownership and vintage. Once tagged, the team can easily curate subsets such as all staff-shot photos with active copyright taken in the last 12 months and move them to active editorial folders. Images with expired licenses can be automatically flagged for archive. This eliminates the manual effort of auditing large image libraries before publication cycles.
3. Life Sciences: FDA data integrity and audit readiness.
Lab imaging is a known weak spot for FDA data integrity. Untracked edits, mismatched timestamps, and images captured on non-qualified instruments are among the issues FDA inspectors cite in 483 observations and warning letters. Remediation typically runs $5 to $15 million, with additional losses if drug approvals are delayed. By extracting EXIF fields such as software, date/time, original versus digitized, and camera serial into the Komprise search index, an organization can proactively identify and curate the risky subset before an inspection surfaces them.
Benefits of the serverless Komprise approach
KAPPA handles the processing and infrastructure at scale, without touching existing applications and without relying on brittle scripts that are hard to maintain as file volumes grow. KAPPA operates as a layer above the storage environment, not inside the application stack.
Importantly, the extracted metadata persists even if the underlying files move across storage tiers, ensuring that compliance, editorial, and AI pipelines can always find and trust the data they need.
Organizations gain:
- Cost-efficient data management by identifying and aging out stale, duplicate, or low-priority images from expensive primary storage;
- Faster image dataset discovery and curation across departments and storage environments;
- Proactive compliance posture for FDA data integrity, HIPAA, and copyright governance;
- Improved operational productivity and reduced time from image capture to usable insight;
- Direct access for AI agents, compliance auditing tools, rights management platforms, and BI systems.
Why this matters now
As AI adoption accelerates across healthcare, life sciences, and media, IT infrastructure teams face growing pressure to make image data accessible, governed, and AI-ready on demand. At the same time, regulatory scrutiny of image integrity is intensifying.
KAPPA data services provide a practical way to meet AI data workflow and preparation requirements for image files by automating EXIF metadata extraction and turning unstructured image libraries into structured, searchable, and governed datasets.
KAPPA data services are currently an early access program for customers. Contact your Komprise account team to discuss specific use cases. To schedule a demonstration and learn more visit: Komprise.ai/KAPPA
Learn more about Komprise for Healthcare, Life Sciences & Genomics, and Media & Entertainment.

